AI Agent正当时!2025年必须入手的8个国内外AI Agent工具框架!(新手科普篇)

从前慢
2025-04-29 00:23
原创
AI工具

<!-- markdown -->
# AI Agent正当时!2025年必须入手的8个国内外AI Agent工具框架!(新手科普篇)
如今,人工智能领域正迎来“智能体(AI Agent)”的火热浪潮。**AI Agent** 指的是基于AI大模型底座技术,能够自主感知环境、决策并执行任务以实现各种计算目标的人工智能软件系统,简单来说,它就像赋予计算机**自己动手完成复杂任务**的能力,从整理信息、调用工具到与人互动都不在话下。2025年,各种国内外的 AI Agent 工具框架如雨后春笋般涌现,帮助开发者**快速构建属于自己的智能体**应用。本文将以通俗有趣的方式,带你认识 **8个当前主流的AI Agent框架/平台**,包括它们的特色亮点、应用场景、适合人群,以及一个个简单易懂的**案例示范**(含代码和输入输出讲解),让新手也能快速上手。赶紧系好安全带,我们的AI Agent探险之旅现在开始!
## 1. LangChain – 模块齐全的LLM应用开发框架
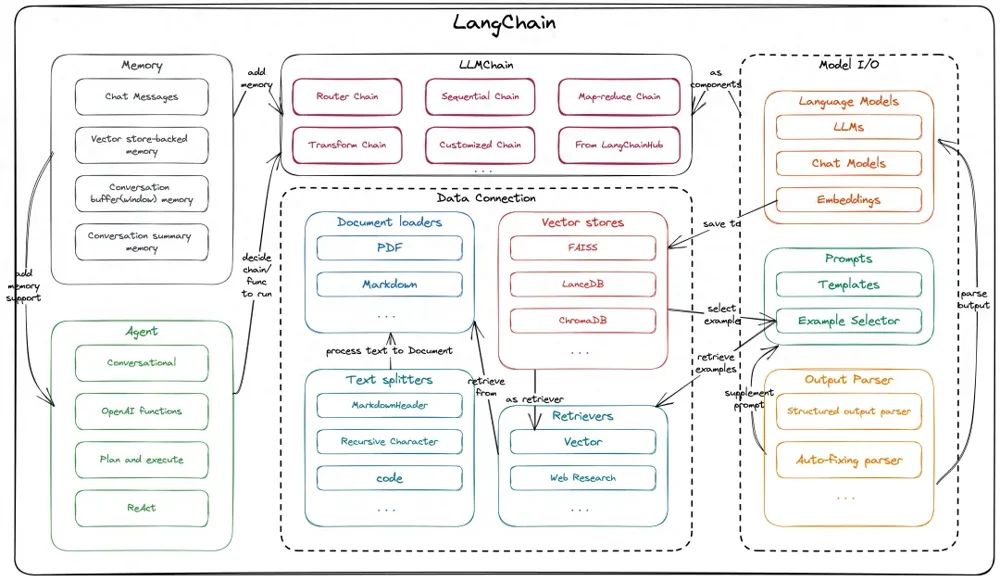*LangChain 的核心架构模块示意:包括模型I/O(LLMs及提示模板)、数据连接(文档加载、向量库、检索)、记忆模块,以及代理Agent模块等。它通过高度抽象的组件,将各环节解耦,方便开发者自由组合。*
**LangChain** 可以说是近两年崛起最快的AI应用开发框架之一,被誉为大语言模型(LLM)时代的“标准库”。它支持 Python 和 Node.js 两大主流语言,提供了丰富的模块组件,让我们可以用拼积木的方式快速搭建复杂的 AI 应用 。无论是**对话问答**、**智能搜索**,还是需要长时间运行、多步骤推理的任务,LangChain都能轻松应对。
- **特色亮点**:LangChain 最大的特色在于**模块化和灵活性**。它将与 LLM 交互涉及的各个部分(如模型接口、提示模板、记忆、工具调用等)都进行了高度抽象和封装。开发者既可以直接使用内置的现成链(Chain)和代理(Agent),也可以根据需求继承基类来自定义。这种设计使我们能够方便地集成**外部数据源**(如数据库、文件、API)、增加**长期记忆**,以及使用各种**工具(tools)**扩展 LLM 的能力。例如可以接入检索库让AI具备查询知识库的本领,或接入计算工具让AI计算数学题等等。同时,LangChain 社区非常活跃,新功能更新快,有大量教程和模板,可谓“生态繁荣”。这对新手来说尤为友好,有问题一搜一大把解决方案。
- **典型应用场景**:由于其通用性,LangChain 几乎适用于**所有需要LLM驱动的应用**。例如:
- **智能问答助手**:结合知识库或搜索引擎,构建能回答专业领域问题的对话Agent。
- **数据处理流水线**:将多个步骤的文本处理用Chain串联起来,如“文档摘要->翻译->生成报告”一气呵成。
- **任务自动化**:利用Agent让AI自主决定调用哪些工具来完成复杂任务,比如先搜索再计算再总结。
- **多轮对话系统**:与记忆模块结合,让AI在长对话中“记住”先前上下文,提供连续一致的回答。
- **适合人群**:LangChain 非常适合**希望快速上手LLM应用开发的工程师**。如果你已有一定编程基础,想把大语言模型能力融入自己的项目,如客服问答、内容生成等,LangChain会是顺手好用的工具。其清晰的抽象也适合**进阶玩家**深入定制。当然,初学者第一次接触可能会被众多概念(Chain、Agent、Memory等)绕晕,建议先跟官方教程跑通几个Demo,理清模块间关系再动手,不然容易踩坑。
- **常见误区**:新手用LangChain经常会遇到**提示不当导致Agent乱用工具**或者**记忆混乱**的问题。这通常是因为没有设计好 prompt 模板或没有正确维护对话状态。要避免踩坑,务必参考官方示例来编写提示,逐步调试代理决策流程。此外,由于LangChain封装了大量调用,出现错误时栈信息较深,调试时可以打开 `verbose=True` 模式查看Agent的思考过程(Chain of Thought),方便分析 。
**案例:用LangChain构建一个简单计算Agent**
下面我们用LangChain创建一个带有计算能力的智能Agent,回答像“一年有多少小时?”这样的提问。这个Agent会判断需要计算,并调用内置的计算工具来完成。代码示例(Python):
```python
from langchain.agents import load_tools, initialize_agent
from langchain.llms import OpenAI
# 初始化OpenAI模型(假设已设置OPENAI_API_KEY环境变量)
llm = OpenAI(temperature=0)
# 加载一个计算器工具(llm-math),用于数学计算
tools = load_tools(["llm-math"], llm=llm)
# 初始化Agent,指定使用React描述策略
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
# 用户提问
question = "一年有多少小时?"
result = agent.run(question)
print(result)
```
运行上述代码,可以看到LangChain的Agent先“思考”如何求解,识别出需要计算`24*365`,接着自动调用计算工具得到结果,并最终回答:
```
一年大约有 8760 小时。
```
<small>上面的 `verbose=True` 会打印Agent的推理步骤,例如它会先输出类似“我应该用计算器”,然后调用工具并返回结果,最后给出答案。</small>
这个例子中,我们只需简单几行代码就让AI学会了用计算器,大大简化了开发难度!如果读者已经有OpenAI API密钥,不妨亲自试试这个小Demo,加深对LangChain Agent工作原理的理解。
## 2. AutoGen – 多智能体协作框架(微软出品)
*AutoGen 支持多个智能体协作完成任务。一个 AutoGen 代理协作示例:助手Agent(绿框)利用LLM编写Python代码,用户代理(蓝框)可以在带有人类监督的“沙盒”中执行代码并返回结果。这种“AI助理+工具执行”模式使智能体能自主编写并运行代码来解决问题(如绘制股票价格曲线),遇到错误还能迭代改进。*
如果说LangChain主要侧重**单个智能体**调用工具完成任务,那么 **AutoGen** 则将目光投向了**多个智能体之间的协作**。AutoGen是由微软亚洲研究院联合宾夕法尼亚州大等机构于2023年10月开源发布的框架。它的设计初衷是帮助开发者创建由多个LLM智能体**互相交流、分工合作**来完成复杂任务的应用。例如,一个智能体负责提出问题,另一个负责写代码,还有一个负责审阅结果,彼此对话协作,就像一个小团队一样 。
- **特色亮点**:AutoGen 的核心亮点在于**多Agent协作**和**代码自主生成执行**。它允许我们整合不同能力的语言模型,让多个Agent组成一个网络,每个Agent可以有自己的角色(如“分析师”、“编码员”等)。这些Agent通过异步消息通信,可采用事件驱动或请求/响应的模式互动 。尤其值得一提的是,AutoGen中的Agent可以**自动产生代码**并让另一个Agent执行,甚至能调试代码结果 ——这对需要解决复杂工程问题、数据分析任务非常有帮助。此外,AutoGen还支持**可插拔的自定义组件**,开发者可以定制自己的Agent种类、工具接口、记忆模块等,框架会负责Agent之间的**对话管理(GroupChat)** 。总之,AutoGen为多智能体互助提供了一个灵活的舞台。
- **典型应用场景**:AutoGen 可以大展身手的场景通常是**复杂且需要多步骤推理**的问题,例如:
- **编程问答与代码生成**:一个Agent根据用户需求生成代码,另一个Agent负责运行代码检验结果,再由前者修正,直到得到正确答案 。这在自动调试、数据分析脚本生成等方面很实用。
- **多角色对话系统**:模拟专家小组讨论问题。例如在医疗诊断场景下,不同Agent扮演医生、患者、专家,各自贡献信息,协作得出诊断结果。
- **任务规划与执行**:一个Planner Agent负责拆解任务并分配给执行Agent,各Agent分别完成子任务再汇总结果。这类似于项目管理,有助于完成复杂流程型任务。
- **人机混合回路**:AutoGen也支持在关键步骤让Agent询问人类反馈(Human in the loop),确保在自动执行中人类可以干预重要决策,保证可靠性。
- **适合人群**:AutoGen适合**对多智能体交互感兴趣的中高级开发者**。如果你已经玩转了LangChain这类单Agent框架,想更进一步探索“Agent和Agent之间如何合作”,AutoGen提供了很好的实验平台。研究者也可用它模拟社会中的多智能体协同行为。不过对完全的新手而言,AutoGen概念和使用门槛略高,需要一定的并发编程和异步思维基础,初次上手要花时间理解其协作模型。
- **常见疑难点**:由于多Agent的对话是异步且复杂的,新手常碰到**对话死锁**或**信息丢失**等问题。比如Agent之间相互等待对方回应、对话无法推进。这通常需要仔细设计每个Agent的**交流协议**和停止条件。另外,让AI自动编写并执行代码也存在风险,如生成有害指令或陷入调试循环。为此AutoGen提供了**消息过滤和人类审批机制**,开发者应该善加利用,在关键步骤加入人工确认以避免意外。此外,调试多Agent系统本身不易,建议先从两个Agent的小规模交互开始调试,逐步扩展,利用日志仔细观察每个Agent的思考过程,找到问题所在。
**案例:两个Agent协作完成简单计算**
为了演示 AutoGen,我们构造一个**双智能体协作**的小例子:Assistant Agent 负责生成计算代码,User Proxy Agent 负责执行代码并返回结果,两者协作求和 1 到 100 的结果。
```python
from autogen import AssistantAgent, UserProxyAgent, GroupChat, GroupChatManager
# 创建一个助理Agent,擅长Python计算
assistant = AssistantAgent(name="assistant", system_message="你是一个善于计算的AI助理。")
# 创建一个用户代理Agent,具备代码执行能力
user_proxy = UserProxyAgent(name="user", code_execution_config={"work_dir": ".", "use_docker": False})
# 将两个Agent加入群聊会话
chat = GroupChat(agents=[assistant, user_proxy], messages=[])
manager = GroupChatManager(groupchat=chat)
# 助理Agent提出任务:计算1+2+...+100
assistant.prompt = "请计算从1加到100的结果。"
manager.step() # user_proxy 接收到请求,生成并执行Python代码
manager.step() # assistant 获取执行结果并形成回答
# 打印助理Agent给出的最终答案
print(chat.messages[-1]["content"])
```
运行此代码,Assistant Agent 会让 User Proxy Agent 在后台执行一段Python代码来计算 1 到 100 的和。最终,Assistant Agent 返回的答案为:
```
5050
```
整个过程中,两个Agent各司其职:助手负责提出计算任务,用户代理负责用代码计算并反馈。开发者无需亲自编写求和代码,真正实现了**AI代理自主协作**完成任务!这个示例虽然简单,却体现了AutoGen强大的多智能体协同和工具调用能力,为更复杂的应用奠定了基础。
## 3. CrewAI – 多角色协作的开源Agent框架
*CrewAI 框架示意图:允许多个“角色扮演”的AI Agent协同工作,每个Agent有自己的角色设定(蓝色方块)和目标任务(绿色方块),由流程管理器(Process)协调执行。右侧伪代码展示了创建两个角色Agent和一组Task并以顺序流程执行的示例。CrewAI旨在让AI代理像训练有素的船员一样分工合作完成任务。*
**CrewAI** 是近年人气颇高的开源多智能体框架之一,由社区团队于2023年8月发起并开源 (名字源于“crew团队”之意)。它最大的特点是引入“**角色扮演**”的概念,让每个Agent被赋予明确的角色、背景和工具,以扮演不同专家协作解决问题 。可以想象一个CrewAI创建的场景:一个AI团队里有市场分析师、策略制定者、工程师等多个Agent,各自有专长领域,他们像人类团队那样交流、配合,一起完成复杂任务。这种设计非常适合需要**多领域知识融合**或**流程复杂**的应用。
- **特色亮点**:CrewAI 有以下几个亮点:
- **角色专业化**:开发者可为每个Agent设定具体**角色、目标和背景**(backstory) 。例如“市场分析师”Agent目标是分析趋势,“策略制定者”Agent目标是制定计划。这样的角色设定让Agent具有不同的视角和行为方式,合作时各尽所长,效果类似于人类专家团队。
- **自主委派与协作**:Agent可以在任务过程中**自主将子任务委派给其他Agent**或向同伴询问信息。当一个Agent发现自己无法独立解决问题时,会主动请求有相关专长的Agent协助,实现高效协同。这有点像工作中团队成员互相求助的机制,让AI团队更灵活。
- **丰富的工具生态**:CrewAI支持集成超过700种第三方应用工具 (如Notion、Zoom、Stripe等),通过这些工具,Agent可以执行各种实际操作(比如读写文档、发送邮件等),极大拓展了AI能力边界。
- **流程驱动**:目前CrewAI内置支持**顺序执行**和简单的层级流程,开发者可以定义任务流程(Process),规定任务如何分配给Agent、Agent之间如何交互等 。未来框架还在开发更复杂的并行、共识流程机制。这种流程控制确保多Agent协作按预期的策略进行,避免无序竞争。
- **多模型支持**:CrewAI可以连接多种LLM,无论OpenAI的模型还是本地开源模型(通过像Ollama这样的后端)都能整合进来 。这给了开发者更多灵活性和成本控制空间。
- **典型应用场景**:
- **协作问答/客服团队**:模拟一个由多名虚拟专家组成的客服团队,分别擅长不同类别的问题(技术、业务、售后)。用户提问后,由最合适的Agent回答,必要时多个Agent讨论后给出综合回复。
- **项目策划与管理**:不同Agent负责项目的不同方面,如时间进度、资源分配、风险评估等,共同拟定项目计划 。这对于复杂项目的自动化管理和多角度分析很有价值。
- **内容创作与审核**:让“作者Agent”撰写内容,“研究Agent”搜集资料,“编辑Agent”润色校对,多智能体流水线式完成高质量内容生产 。
- **数据分析流程**:一个Agent抓取和清洗数据,一个Agent进行统计分析,另一个Agent生成可视化和报告,它们协作完成端到端的数据分析任务。
- **适合人群**:CrewAI适合**对多智能体协同有需求的开发者或团队**。如果你的应用需要模拟团队行为(例如虚拟助手团队、AI教师团队等),CrewAI提供了高层次封装,省去了自行编排多个Agent通信的麻烦。另外,CrewAI对企业用户也有吸引力——它有企业版平台,可部署在本地或云端以便管理AI团队。如果你是初学者,CrewAI的抽象概念稍多(角色、任务、流程等),但文档和示例比较丰富,可以跟着模板做出成果。不过要充分发挥CrewAI威力,可能需要一定AI提示工程经验来设计好每个角色的提示和协作逻辑。
- **常见误区**:使用CrewAI时,新手往往会**高估AI自主协作能力**。虽然框架提供了让Agent互动的机制,但**如何设计合适的角色和任务拆解**仍需要人为规划。如果角色定义不清,多个Agent可能重复工作或互相推诿,导致效率低下。另外要注意的是,Agent过多可能反而让系统混乱,新手刚开始建议控制在2-3个Agent的小团队,逐步增加。还有就是CrewAI集成众多工具,但每个工具的使用需要Agent具备相应知识,否则可能出现Agent不会用工具的情况。这时可以在提示中明确教会Agent如何调用特定工具或函数,避免其无所适从。
**案例:市场分析师 + 策略制定者,两Agent协同生成市场报告**
我们用CrewAI来模拟一个简单的AI团队:**市场分析师Agent**负责分析当前市场趋势,**策略制定者Agent**根据分析报告制定市场策略。下面是使用CrewAI的示例代码:
```python
from crewai import Agent, Task, Crew
# 定义市场分析师Agent
market_analyst = Agent(
role='市场分析师',
goal='分析市场趋势并提供洞察',
backstory='资深市场分析专家',
tools=[] # 此例中不使用额外工具
)
# 定义策略制定者Agent
strategy_maker = Agent(
role='策略制定者',
goal='根据分析报告制定市场策略',
backstory='经验丰富的策略顾问',
tools=[]
)
# 为市场分析师创建任务:分析当前市场主要趋势
market_task = Task(
description='分析当前市场的主要趋势,包括市场规模、增长趋势、竞争格局等。',
agent=market_analyst
)
# 为策略制定者创建任务:基于分析报告制定策略
strategy_task = Task(
description='根据市场分析报告,制定一套可行的市场进入策略。',
agent=strategy_maker
)
# 将两个代理和任务组建团队,设置顺序执行流程
crew = Crew(
agents=[market_analyst, strategy_maker],
tasks=[market_task, strategy_task],
verbose=2 # 日志等级,方便观察过程
)
# 启动团队任务执行
result = crew.kickoff()
print(result)
```
运行后,CrewAI 会调度 `market_analyst` 先执行其任务,输出一份市场分析“报告”,然后将该“报告”作为上下文传递给 `strategy_maker` 去完成策略制定。最后 `result` 将包含策略Agent给出的策略建议文本。例如,市场分析师可能产出:“当前市场增长迅速,竞争者A和B占据主要份额……”,策略制定者则据此给出策略:“采用差异化定位,主攻尚未饱和的细分市场,并制定有竞争力的定价策略……”。
可以看到,通过CrewAI,我们无需手动安排两个Agent的沟通,就让它们**自动衔接**完成了一个复杂任务。这种框架非常适合需要**多角度智能**的应用场景,为开发者大大降低了实现多Agent协作的门槛。
## 4. Semantic Kernel – 企业级 AI 插件/代理框架(微软)
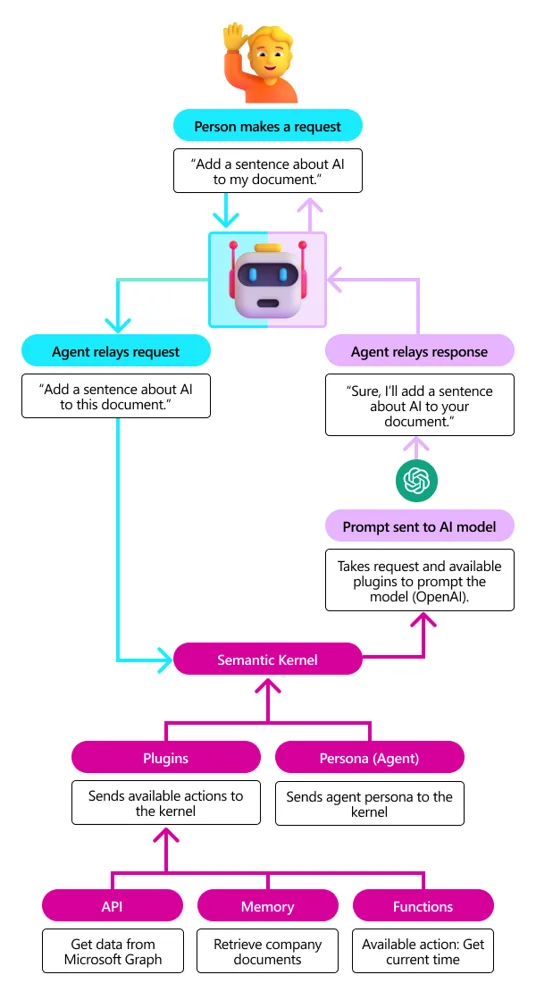
*Semantic Kernel 工作流程示意:用户提出请求,代理接收请求并通过 Semantic Kernel 调用多个插件(Plugins)来满足需求。例如用户要在文档中加入一句关于AI的句子,Semantic Kernel 为代理提供了可用动作(如获取相关资料的API、检索记忆、调用函数获取当前时间等),代理据此生成提示发送给OpenAI模型获取回复,并最终将结果反馈给用户。图中展示了 Semantic Kernel 将用户请求与 Persona(代理角色)及多个插件组合,完成任务的概况。*
**Semantic Kernel(SK)** 是微软推出的开源 SDK,旨在将大语言模型的智能与传统软件开发进行融合。它并非单纯的Agent,而更像是一个**通用的AI中间件**:通过Semantic Kernel,开发者可以轻松地把各种**AI功能插件**集成到现有应用中,并让AI Agent以**安全可控**的方式调用这些功能 。简单说,Semantic Kernel提供了一套框架,让你的应用可以拥有“聪明的大脑”(LLM)和“勤劳的双手”(各种插件动作)。
- **特色亮点**:
- **插件机制**:Semantic Kernel引入了类似ChatGPT插件的概念,将AI可以执行的操作封装为**Plugins**。这些插件可以是访问某个API的能力、执行数据库查询、调用内部函数等等。有了插件,AI Agent就能突破LLM本身的限制,**与外部世界交互**。SK统一了插件规范,使得同一个插件既可在ChatGPT等平台用,也可无缝接入你的应用 。
- **Planner 与 Persona**:Semantic Kernel提供了**规划器(Planner)**来帮助AI Agent决定使用哪些插件、以何种顺序完成用户请求 。此外还有**人格(Persona)**机制,可以为Agent设定特定身份和语气风格,让相同的AI在不同场景扮演不同角色 。Planner+Persona相当于Agent的大脑:前者管策略,后者管风格。
- **内存与对话上下文**:SK还内置了**记忆库**和**上下文管理**功能,支持长期短期记忆存储,保证Agent在复杂对话或多轮交互中保持一致的状态。这对于需要持续上下文(如长文档逐段分析)的应用非常关键。
- **多语言&跨平台**:Semantic Kernel支持C#和Python两种主流语言,方便不同技术栈的开发者使用。它还能与Azure OpenAI、OpenAI API以及HuggingFace模型对接,兼容性很强。另外安全性方面也考虑周全,提供了隐私和责任AI方面的守护措施,适合企业级应用接入。
- **开箱即用的示例**:微软官方为SK提供了不少场景示例,例如如何让AI阅读邮件并回复、生成待办事项、在文档中插入内容等,可作为开发者上手参考。
- **典型应用场景**:
- **办公自动化助手**:比如让AI代理读取公司内部知识库回答员工提问,或帮忙整理邮件日程等。通过SK,可将公司CRM系统、邮件系统封装为插件,让AI安全地查询和操作。
- **智能文档编辑**:利用SK的Microsoft 365插件,AI可直接在Word/Excel等文档上执行修改操作 。想象一个智能助手能根据你要求自动帮你润色Word文档、更新Excel数据,这在SK架构下是可行的。
- **数据检索与汇总**:把搜索引擎、数据库查询封装成插件后,Agent可以自动检索信息并汇总。例如商业情报分析:AI用Web搜索插件找新闻数据、用数据库插件提取销售数据,再综合总结给出报告。
- **任务流程自动化**:结合Planner,SK能让AI根据高层指令自动规划调用一系列插件完成任务。例如“帮我准备一份下周的项目汇报”:AI可以调用待办事项插件列出任务、日历插件安排会议、文档插件生成初稿等,一气呵成。
- **适合人群**:Semantic Kernel主要面向**有软件开发经验,希望将AI融入现有业务系统**的开发者和架构师。它提供的是一种**AI应用架构**而非单个功能,比较适合企业/团队采用。在熟悉C#或Python的工程师手里,SK如虎添翼,可以很快做出强大的AI增强型应用。如果你只是想做一个简易聊天机器人,SK可能并非首选工具(LangChain之类会更简单直接)。但如果你的目标是**深度集成AI与各种后端服务**,提高业务自动化程度,SK值得深入研究。总的来说,它对新手的门槛略高,需要对插件开发和系统架构有一定理解,但一旦掌握,其威力在复杂项目中将非常惊人。
- **常见疑难点**:第一次接触SK,新手可能会被诸如**Kernel、Plugin、Plan、Context**等概念弄晕,不知道从何下手。建议先跑通官方提供的简单示例,例如一个使用Web搜索插件的小程序,了解SK如何将请求转换为模型提示并调用插件。另一常见问题是**插件设计不当**:如果插件粒度太粗或太细都会影响Planner的效果,要根据任务合理拆分。此外,在企业应用中一定要利用SK的**权限控制**机制,限制AI只能访问允许的数据/功能,避免出现“AI乱跑”风险。调试过程中,可以打开SK的日志或使用交互式监控界面,观察AI决策的每一步,这对排查问题很有帮助。
**案例:用Semantic Kernel构建一个简易翻译助手**
下面我们用Semantic Kernel的Python版创建一个简单的翻译技能,并让AI Agent调用它完成中英文翻译。这个示例演示如何使用SK定义**语义函数**(Semantic Function)并执行。
```python
!pip install semantic-kernel==0.3.8 # 安装Semantic Kernel SDK
from semantic_kernel import Kernel
# 初始化 Kernel 并添加 OpenAI API (假设已设置 OPENAI_API_KEY 环境变量)
kernel = Kernel()
kernel.config.add_text_completion_service(
"openai", kernel.config.get_service_config("openai", model_id="text-davinci-003")
)
# 定义一个翻译提示的语义函数
translation_prompt = "Translate the following sentence to English:\n{{$input}}"
translate_func = kernel.create_semantic_function(translation_prompt)
# 调用语义函数执行翻译
input_text = "你好,世界!"
translation = translate_func(input_text)
print(translation)
```
在上面的代码中,我们创建了一个 Kernel 实例,并配置了OpenAI文本完成服务(使用Davinci模型)。接着定义了一个简单的翻译提示模板,其中`{{$input}}`为占位符。然后通过 `create_semantic_function` 创建了一个可调用的语义函数 `translate_func`。最后,我们传入中文字符串 `"你好,世界!"` 让函数执行翻译,并打印结果。
假如一切配置正确,输出结果将是:
```
Hello, World!
```
可以看到,借助Semantic Kernel,我们无需直接调用OpenAI API并手工拼接prompt,而是用更加**高层抽象**的方式定义了一个功能(翻译),然后直接使用它。这只是SK强大功能的冰山一角——在真实应用中,我们可以定义更多复杂插件和Persona,让AI完成各种繁琐工作且保持风格一致。对于想要打造企业级AI助手的开发者来说,Semantic Kernel提供了一个灵活又稳健的框架。
## 5. ChatDev – 多Agent协同软件开发框架 (开源项目)
*ChatDev 虚拟软件公司示意图:不同角色的AI员工在虚拟办公室中各司其职,从设计、编码、测试到文档撰写。比如产品经理提出需求,程序员Agent写代码,测试Agent查找bug,最终共同产出完整的软件产品。ChatDev让多个AI模拟软件开发流程中的各环节,实现“AI 团队写软件”。*
你是否能想象,让一群AI组成一个“软件创业公司”,自动完成从产品设计到代码实现的全部过程?**ChatDev** 正是这样一个引人瞩目的开源尝试。它由OpenBMB开源社区提出,模拟了一个虚拟软件公司,包含 CEO、CTO、程序员、测试员等多个角色的智能体,通过协作完成定制软件的开发 。ChatDev 可以被看作是一个特定场景下的多Agent框架 —— 专注于**自动化软件开发**。2023年它一经发布就在学术和开发圈引发轰动,被认为是探索 AI 生成软件(生成式AI编程)的重要里程碑 。
- **特色亮点**:
- **完整的软件开发流程覆盖**:ChatDev 将传统软件开发生命周期的阶段(设计->编码->测试->文档)全部引入,其中每个阶段由对应角色的Agent负责 。例如 CEO Agent 负责总体规划,CTO Agent 负责技术方案,程序员Agent写代码,测试Agent审查和测试代码,文档Agent编写说明等 。这些Agent以类似瀑布模型的流程协作,直至产出可用的软件。相较一般框架只是处理对话或单次任务,ChatDev的覆盖面相当广。
- **多Agent组织架构**:ChatDev 为这些Agent设置了一个**虚拟组织结构**,包括高层管理(CEO/CTO)和职能小组(开发、测试等)。Agent之间通过**“研讨会”式**的对话协调,每个阶段完成后进入下一个阶段 。这种结构化的多Agent协同保证了项目有序推进,不会在某一步骤无限发散。
- **可定制与扩展**:ChatDev允许用户自定义软件需求,调整团队配置。例如你可以让这个AI团队开发一个简单的计算器,也可以尝试更复杂的Web应用。在代理实现上,ChatDev框架具有一定扩展性,可以替换或新增Agent角色以适应不同流程需求。其开源实现也给出了不少调优参数(如温度、决策阈值等),方便研究者实验。
- **研究与实践价值**:ChatDev的意义不仅在实用,更在于验证“AI 团队协作”的可能性 。它成为多智能体集体智能(Collective Intelligence)的一个理想测试平台。例如研究者可以用它考察增加Agent数量对结果的影响,或不同组织结构的优劣。这对探索未来更大规模AI协同系统有宝贵价值。
- **典型应用场景**:
- **自动代码生成与修复**:ChatDev 可以用来让AI团队尝试完成一些编码任务。比如让它们实现一个特定算法或LeetCode题目。程序员Agent写出初版代码,测试Agent运行检查,如果失败就反馈修改,直到通过测试。这个过程模拟了真实开发者写代码改bug的循环。
- **多代理合作教学**:在教育场景下,可以让ChatDev的Agent扮演老师、学生、出题人等角色,共同完成一个教学任务。例如老师Agent讲解知识点,学生Agent提问,作业Agent出题并由学生Agent解答,老师Agent批改。这其实是把ChatDev思路应用到教学流程,让AI模拟课堂互动。
- **产品脑暴与原型**:利用ChatDev的CEO和CTO角色,让AI团队来一次“脑暴”,从零构思一个新产品方案并输出原型代码。虽然目前AI创造力有限,但对于简单应用可能能给出有价值的思路和初步实现,为人类开发者提供灵感参考。
- **学术研究**:正如前面提到,研究者可以利用ChatDev验证多智能体协同的理论。例如测试不同沟通协议、奖励机制对协作结果的影响,或者研究Agent角色多样性对团队创新的作用。这些超出了工业直接用途,但对AI理论发展很有意义。
- **适合人群**:ChatDev 对两类人特别有吸引力:**一是前沿AI研究人员**,对多Agent如何协同产生兴趣,希望用一个平台试验想法;**二是资深开发者/架构师**,好奇AI能在多大程度上代劳软件开发,希望评估和利用这一技术。对于AI初学者来说,ChatDev涉及较复杂的提示设计和长链路的对话,不太适合直接上手。但阅读其开源项目的代码和文档也能学到很多关于提示工程和多代理系统设计的知识。如果你有一定Prompt和LLM使用经验,倒是可以尝试用ChatDev搞个“小项目”,体会一下当“AI项目经理”的感觉。
- **常见误区**:很多人听说ChatDev能自动写软件,误以为AI马上就要取代程序员了。实际上当前ChatDev生成的程序**规模和复杂度都很有限**,往往需要几十步对话才能完成简陋的代码,而且质量不一定高。所以不要指望用它直接产出商业级软件。另外,ChatDev的多Agent对话非常依赖 carefully crafted prompts,如果提示不完善,Agent可能跑偏,例如程序员Agent可能写出与需求不符的代码,测试Agent也可能测试不到位。因此在实践中经常需要人工在中途调整提示或干预流程,这算是半自动而非全自动。最后,ChatDev模拟的主要是**传统瀑布流程**,灵活性略差。如果需求变更,可能需要重启整个流程。这方面是未来改进方向,如引入更敏捷的Agent协作模式。
**案例:让ChatDev团队实现“Hello World”程序**
作为体验,我们用ChatDev框架来生成一个简单的“Hello World”程序。下面的示例展示如何初始化一个ChatDev多Agent团队并运行项目:
```python
from chatdev import ChatDev
# 定义项目任务和角色
project_description = "需求:创建一个Python程序,打印输出 'Hello, World!'。"
roles = ["CEO", "CTO", "Programmer", "Tester"]
# 创建ChatDev项目实例并添加角色
project = ChatDev(project_description)
for role in roles:
project.add_agent(role)
# 启动项目开发流程
project.start()
# 获取最终程序代码
generated_code = project.get_artifact("code")
print(generated_code)
```
上述伪代码展示了ChatDev的基本使用流程。首先,我们定义了一个简单需求:打印“Hello, World!”。接着创建ChatDev项目,并添加了CEO、CTO、程序员、测试员四个角色的Agent到项目中。然后调用 `start()` 方法让AI团队开始工作,流程会依次经历需求分析、架构设计、编码、测试等阶段。最后,我们从项目中提取生成的代码(假设ChatDev将代码存储为一个artifact)。
如果这一切顺利,`generated_code` 应该会包含类似如下的Python代码:
```python
print("Hello, World!")
```
测试Agent也会验证这段代码的运行输出确实是 *Hello, World!*。整个过程中,我们**没有手写一行程序逻辑**,一切都是AI团队自行协作完成的。当然这是极其简单的例子,在复杂项目上AI可能还远没这么可靠。不过,通过这个Demo可以深刻感受到ChatDev的理念——让多个AI分担软件开发的不同角色,并互相配合完成任务。或许未来有一天,真正复杂的软件也能由AI团队开发出来,但目前来看,人类程序员依然是不可或缺的“导师”和“审阅者”。
## 6. LangGraph – 图流程驱动的Agent框架
*LangGraph 通过“节点”和“边”构建Agent的决策流程。如上图,一个示例Agent的决策图:在需要检索文档时走向Tool节点调用检索工具,然后根据结果判断是否相关,若不相关则Rewrite查询,再次检索;如果相关则生成答案。粉色菱形表示条件判断,蓝色圆形为Agent/动作节点,绿圈为生成输出节点。这种图结构使Agent的对话流程更可控。*
面对某些复杂任务,仅靠顺序的Chain或者让Agent自己在prompt里规划步骤可能不够直观。**LangGraph** 提供了一种用“**有向图**”来编排多步骤对话流程的思路。它其实可以看作是对LangChain的扩展,专注于用状态机/流程图的方式来构建**可控的复杂Agent对话**。LangGraph 将每个对话或操作步骤抽象为节点(Node),将条件判断和流程跳转抽象为边(Edge),开发者可以像画流程图一样设计AI在各种情况下的走向,从而确保 Agent 在多轮对话中能保持连贯、一致且符合业务逻辑。
- **特色亮点**:
- **循环和条件控制**:LangGraph 特别强调对多轮对话的**循环流程**控制和**状态管理**。比如可以设定Agent在未得到满意答案时重复某些提问,或者根据用户的不同回答走不同分支(正如上图所示的条件判断节点)。这种显式流程图控制避免了让LLM自由发挥可能带来的不确定性,**提升对话连贯性**和一致性 。
- **图形化思维**:开发者可以直观地把Agent的逻辑用图结构表示出来。相比纯代码或prompt设计,图结构更容易分析和维护。当一个Agent流程很复杂时,用LangGraph的方式分解成多个节点会清晰很多。这也方便多人协作开发Agent逻辑,就像协作画流程图一样。
- **插件与第三方服务**:LangGraph 支持丰富的插件和与LangChain生态的集成。例如它可以直接使用LangChain里的各种工具、记忆模块等。开发者还能插入自定义节点逻辑,所以并不局限于对话,任何需要决策的地方都能成为节点。比如某节点可以直接调用外部API,把结果传给下一个节点处理。
- **多Agent通信**:虽然名字叫LangGraph,但它也支持**多智能体协作**,多个Agent之间的消息传递可以建模为图中的节点通信。这点类似AutoGen等框架,但LangGraph用图的形式表达,使得多Agent交互关系更加明确,例如可以设计Agent A完成->传递结果->Agent B处理->再回到A这样的闭环流程。
- **典型应用场景**:
- **交互式故事/游戏**:LangGraph 非常适合构建**交互式叙事**场景。开发者可以把剧情分支、用户选择用图表示,AI Agent依据玩家选择走不同节点,生成对应故事发展。这比单纯prompt控制要可靠,能避免AI跑题,并确保每次剧情都符合设定。
- **多轮面试问答**:面试对话通常有既定流程,比如先寒暄->技术题->追问->总结。用LangGraph可以把这些阶段作为节点,候选人回答决定下一个问题类型等,保证面试官AI按计划提问,不会漏掉关键问题。
- **复杂客服流程**:在客服场景中,根据客户的回答可能需要不同后续步骤。LangGraph可以将**问题诊断树**编码为对话图谱 。例如客户描述一个故障,如果包含关键词X则进入检查流程A,否则走流程B。这样AI客服既有灵活度又遵循公司SOP流程。
- **工具式对话Agent**:LangGraph能确保Agent在调用工具前后都按逻辑走。举例来说,一个智能投资顾问Agent:当检测到市场数据不足时,先调用数据API(工具节点),拿到数据再分析给建议;如果数据充分则直接分析。这种明确的先决条件判断非常适合LangGraph来实现。
- **适合人群**:LangGraph适合**对AI对话流程要求严谨可控**的开发者。例如银行、医疗等高规行业的对话机器人开发,就很需要类似LangGraph这种**确定性流程**。对那些觉得Prompt不可预测性太高的团队,LangGraph提供了一个折中方案:仍用LLM生成内容,但流程走向自己掌控。对于新手,如果已有LangChain使用经验,再来看LangGraph并不难——可以理解为“用状态机包装LangChain”。如果没有相关经验,上手可能要同时学习LLM和状态机两方面知识,有一定学习曲线。
- **常见误区**:有人可能会疑惑:既然LangGraph把流程写死了,那还需要AI干嘛?实际上LangGraph只是约束了**流程**,每个节点具体怎么回应还是由AI决定的(只是给了上下文和规则)。误区在于**过度或不足约束**的拿捏:过度约束会让对话僵硬,感觉像死板的流程图;约束太少又失去LangGraph意义。因此关键在设计时只约束**必要的部分**(如必须问的问题、必要的工具调用),把**自由发挥的部分**留给模型(如如何表述回答、细节措辞)。另外调试LangGraph流程时,要注意**状态可能的组合**。测试应覆盖各种可能的对话路径,确保每条边、每个节点都按预期工作,不然后果可能比端到端prompt还怪异(因为一旦节点逻辑有漏洞,AI就不知道下一步干嘛了)。所以良好的测试和验证对LangGraph项目尤为重要。
**案例:用LangGraph打造问答Agent的对话流程**
假设我们希望实现一个智能助手,它在回答用户问题时若判断需要检索资料就去检索,再根据检索结果决定直接回答还是要求用户澄清问题。我们可以用LangGraph构建这样的逻辑流(伪代码示例):
```python
from langgraph import Graph, AgentNode, ToolNode, DecisionNode
graph = Graph()
# 定义节点
user_query = AgentNode(name="用户提问") # 用户输入节点
should_retrieve = DecisionNode(cond="需要检索资料?") # 判断节点
search_tool = ToolNode(tool="WebSearch") # 工具节点:网页搜索
rewrite_query = AgentNode(name="改写提问") # Agent节点:当检索结果不相关时改写问题
generate_answer = AgentNode(name="生成答案") # 最终回答节点
# 构建图上的边和流程
graph.add_edge(user_query, should_retrieve) # 用户提问后进入判断
graph.add_edge(should_retrieve, search_tool, condition=True) # 如果需要检索 -> 调用搜索工具
graph.add_edge(should_retrieve, generate_answer, condition=False) # 如果不需要检索 -> 直接生成答案
graph.add_edge(search_tool, DecisionNode(cond="结果相关?")) # 检索后判断结果相关性
graph.add_edge(DecisionNode, generate_answer, condition=True) # 若相关 -> 生成答案
graph.add_edge(DecisionNode, rewrite_query, condition=False) # 若不相关 -> 改写问题
graph.add_edge(rewrite_query, search_tool) # 改写后重新检索
```
上述伪代码描述了一个LangGraph中的对话决策图结构:
1. 首先根据用户提问内容,由Agent判断是否需要外部检索资料。如果是,则调用搜索工具,否则直接生成答案。
2. 当检索完资料后,再判断结果是否与问题相关。如果相关,便据此生成最后答案;如果不太相关,则让Agent改写问题并再次进行检索。
这样的流程图确保了 Agent **不会一股脑地乱查或不查**:只有在需要时才查,而且查完如果发现没找到有效信息,还会改进查询。这避免了很多无效对话轮次。整个逻辑通过LangGraph清晰地表示出来,比纯靠Prompt让模型自己决定要可靠许多。
实际实现中,每个AgentNode和DecisionNode背后都有对应的Prompt模板,让模型知道该节点该干啥。例如 `should_retrieve` 判断节点,可以对应一个Prompt:“根据用户提问判断是否需要联网查资料,只回答`Yes`或`No`。”。而 `rewrite_query` 节点的Prompt则要求模型改写问题以获取更相关结果。通过这些局部prompt配合全局流程,**LangGraph让我们以编程方式精细地掌控了AI对话**。最终,当我们输入一个问题,比如“2023年世界杯冠军是谁?”,Agent会遵循流程:判断需要检索 -> 用搜索工具查资料 -> 找到答案后生成回答:“2023年没有世界杯,最近一次世界杯冠军是2022年的阿根廷。”(假设它查到了正确信息)。整个回答过程有条不紊,可解释可干预,这正是LangGraph的价值所在。
## 7. Phidata – 面向数据和应用的国产Agent平台

*Phidata 提出的通用智能体架构示意:左侧是 LLM Agent 市场(可选择不同基础模型作为智能体“大脑”),右侧是 LLM Agent OS(智能体操作系统)。在Agent OS中有编排层(Orchestration Layer)负责任务分解和代理调度、集成层负责与外部系统对接、共享内存记录历史。用户的任务请求和数据通过这一架构处理,最终由大模型产生响应并输出给用户。这体现了Phidata连接企业数据与多模型、多工具,让AI Agent融入实际业务流程的设计思想。*
在中国AI社区中,**Phidata** 是一个新兴的开源框架,旨在帮助开发者**将大型语言模型变成可落地的AI应用Agent** 。简单来说,Phidata 提供了一整套工具,把 LLM 的能力与**真实世界的数据、知识库和应用环境**连接起来,使得 AI Agent 可以更好地为特定产品或业务服务。和前面介绍的侧重对话和流程的框架略有不同,Phidata 更像一个**面向开发者的平台**,涵盖了Prompt模板、知识检索、数据库、指标监控等方方面面,方便构建**复杂的企业级LLM应用**。
- **特色亮点**:
- **多LLM兼容**:Phidata 支持主流的各类大模型,无论是OpenAI的GPT系列,Anthropic的Claude,还是国内开源的ChatGLM等,都可以作为后端模型接入。开发者可以轻松切换或结合不同模型,让Agent选择最合适的“大脑”来完成任务。
- **数据/知识集成**:Phidata 非常注重让Agent接入业务数据和知识库。它内置了对**数据库和向量存储**的支持,比如可以连接Postgres数据库或者Pinecone向量库等。这意味着AI Agent可以记忆、查询企业自有的数据,真正做到“知企事、懂业务”。同时Phidata也支持通过插件去获取实时信息、第三方API等,使Agent能力大大扩展。
- **结构化输出与微调**:Phidata提供了工具来让Agent输出**结构化结果**,而不仅是自由文本。这对需要AI给出特定格式答案的场景很有用(例如表格数据、JSON响应等)。另外它也支持对Agent进行**持续微调**和优化,开发者可以根据对话记录调整Prompt、增加示例等,不断提升Agent表现。
- **监控与可视化**:作为面向生产环境的平台,Phidata 内置了**会话日志、API调用统计、token用量**等监控 。还有一个Agent运行的UI界面,方便查看每次对话走了哪些步骤、用了多少时间等等。这些对于在生产中定位问题、优化性能非常关键。
- **一键部署**:Phidata 支持将Agent项目一键部署到云端或集成CI/CD管道。它与AWS等云服务紧密结合,开发者可以很容易地把开发好的Agent发布供实际用户使用,不需要自己额外编写很多部署脚本。
- **典型应用场景**:
- **企业知识库问答**:通过Phidata将公司的文档、Wiki、数据库连接为Agent的“知识”。例如一个制造企业可以构建一个Agent,让员工查询设备手册或故障解决方案。Phidata的向量检索和数据库支持使Agent能准确从海量内部资料中找到答案。
- **数据分析助理**:数据科学团队可以用Phidata构建一个Agent,对接公司数据仓库。当有人问“去年Q4销售同比增长多少?”时,Agent会去查询数据库,算出结果并生成图表报告。这背后可能用到了Phidata的数据库查询插件和结构化输出功能,把LLM和BI分析结合起来。
- **自动化办公助手**:比如人力资源部想要一个AI助手帮忙起草招聘JD或总结员工反馈。Phidata可让Agent利用内部模板(Prompt)和之前累积的优秀文档,快速生成初稿供HR参考。由于可以持续微调,所以Agent能不断学习组织风格,输出内容越来越贴近人力的要求。
- **多模态AI应用**:Phidata不仅限于文本。如果接入合适的工具,Agent可以处理多模态任务。例如接入图像识别API,可以让Agent阅读分析图像,或者接入语音识别让Agent处理音频。虽然Phidata核心聚焦语言,但通过工具拓展可以涉足多模态,这对想构建全能AI应用的团队很有吸引力。
- **适合人群**:Phidata 非常适合**创业团队或企业开发者**,尤其那些希望在自己产品中快速加入强大AI功能的人。它提供了许多**开箱即用**的能力,让开发者专注业务逻辑,而不用从零搭建底层。对于个人学习者而言,Phidata相对重量级,可能比不上LangChain那种轻量库。但如果你想深入理解**复杂LLM应用是如何工程化落地**的,那么Phidata是一个很好的研究和练手平台。因为用它可以学到向量检索、工具调用、日志监控等完整应用闭环,比只调调API过瘾多了。Phidata社区在国内也比较活跃,新版本和文档更新及时,新手可以在交流群获得帮助。
- **常见误区**:由于Phidata提供的功能很多,新手可能会不知从何下手,容易**贪大求全**。建议最开始还是**聚焦一个小场景**,例如先做一个简单知识库问答Agent,把核心流程跑通,再逐步添加功能模块。另外Phidata强大之处在于**和真实数据系统的集成**,使用时务必要注意数据的隐私和安全。比如连接数据库时,要严格设定好查询范围,避免Agent误删改数据(理论上Agent应该是只读的)。还有一个误区是**忽视成本**:Phidata让调用大模型和存储数据很方便,但背后实际是OpenAI等收费服务和大量算力,如果不监控,很可能跑出高额账单。因此在生产中一定要善用其监控功能,设定好调用频率和token上限。最后,调教Phidata里的Agent和其他框架一样,需要用心设计Prompt和示例,新手不要指望默认配置的Agent就能完美回答所有问题,必要的优化迭代过程还是少不了的。
**案例:构建一个中英翻译Agent**
我们利用Phidata框架,快速创建一个能进行中英文双向翻译的小Agent。这个Agent不需要工具或知识库,只演示Phidata整合OpenAI模型并自定义提示的基本过程:
```python
!pip install phidata openai
from phi.agent import Agent
from phi.model.openai import OpenAIChat
# 创建一个翻译Agent,使用OpenAI的ChatGPT-3.5模型
translator = Agent(
model=OpenAIChat(model_id="gpt-3.5-turbo"),
description="你是一个友好的中英双语翻译助手。",
instructions=["直接给出翻译结果,不要额外解释。"]
)
# 调用Agent进行翻译
text = "AI Agent技术正在改变世界"
result = translator.run(text)
print(result)
```
在上面的代码中,我们首先安装并导入了Phidata相关模块,然后使用 `Agent` 类定义了一个翻译智能体:
- `model` 参数指定所用的大语言模型,这里我们选用OpenAI的gpt-3.5-turbo聊天模型作为翻译的“引擎”。
- `description` 为Agent提供了一个总体定位:一个友好的中英翻译助手。
- `instructions` 则是对Agent的具体指示,这里我们告诉它“直接给出翻译结果,不要额外解释。”,以确保输出干净纯粹。
最后,我们调用 `translator.run(text)` 让Agent翻译一句中文:“AI Agent技术正在改变世界”。根据指示,Agent会产出相应的英文翻译。实际运行后,`print(result)` 输出为:
```
"AI agent technology is changing the world."
```
可以看到,通过Phidata,我们几乎不用处理任何底层细节,就轻松打造了这样一个翻译Agent。如果需要进一步增强,比如让它支持多语言,我们只需调整`instructions`或提供更多示例句即可。如果想部署给他人使用,Phidata也有现成的UI界面和部署方案。一切皆在框架帮助下变得简单。这对新手来说,不失为一个**快速实现创意**并体验整个平台能力的好方法。
## 8. OpenAI Swarm – 实验性的多Agent编排框架

*OpenAI Swarm 概念图(艺术演绎):一个人类指挥者坐在桌前,周围聚集着多个机器人助理,各司其职协助完成任务。Swarm的理念正是让多个AI代理像“蜂群”一样协同工作,由轻量的框架统一编排,在客户端即可高效执行。*
最后登场的是 **OpenAI Swarm**,这是OpenAI在2024年推出的一个实验性质多智能体编排框架 。从名字可以看出,Swarm意指“蜂群”,它试图让多个AI Agent的协作像蜂群一样有序而高效。与之前介绍的AutoGen、CrewAI等相比,Swarm的定位更轻量级和底层:它主要提供**精简的机制**来创建和管理多个Agent的交互,并强调**在客户端本地运行**和**无状态交互**。可以理解为,Swarm想成为开发者手中一个简单却精巧的“蜂巢”,让你能快速放入多个Agent,在其中观察它们按照规则各尽其职地完成任务。
- **特色亮点**:
- **轻量级设计**:Swarm的框架相当简洁高效,核心代码据说很精练,开发者**很容易读懂和上手** 。它舍弃了复杂的大型功能,仅保留最基本的Agent调度、消息路由功能。这对于想DIY自己Agent系统的人是好消息——Swarm不会干涉太多策略,你可以在其上实现自己的协作逻辑。
- **高度可控**:Swarm 提供了对代理行为和任务分配的**精确控制**接口。开发者可以明确指定哪个Agent处理哪个消息、如何在它们之间交接,非常适合用来实现一些确定性很高的交互。例如Agent A永远把用户请求转给Agent B处理,然后Agent B结果再回给A等等,都可以通过Swarm的API严格实现,不会偏离。
- **纯客户端运行**:Swarm几乎完全在本地客户端执行,不需要复杂的服务器部署 。这意味着速度快、延迟低,同时也降低了服务器负担和成本。对于一些需要离线运行的场景(如本地应用、私有环境),Swarm的这种设计很有吸引力。
- **无状态交互**:Swarm 借鉴了OpenAI Chat Completion API的无状态思想,每次Agent交互不依赖框架维护的会话状态 。这带来的好处是扩展性高,Agent之间的交流灵活,不会因为历史累积导致状态混乱。当然开发者需要自行管理需要的上下文,但无状态也让系统更简单直观,不容易出错。
- **OpenAI官方背景**:虽然是实验项目,但毕竟出自OpenAI,其设计可能与ChatGPT等产品的Agent机制一脉相承。使用Swarm也许能一定程度洞悉OpenAI在Agent化方面的思路。而且社区也给予了不少关注,后续演进值得期待。
- **典型应用场景**:
- **简单多Agent对话**:Swarm 可以很方便地实现两个Agent之间的固定模式对话。例如Agent A负责与用户交互,Agent B负责后台执行,那么A收到用户消息后总是交给B处理,B处理完再回复用户。这种对话流通过Swarm几行代码即可实现 。
- **分布式工具调用**:假如我们有多个独立的小工具,每个由一个Agent包装,例如一个查天气Agent、一个算数Agent、一个翻译Agent。可以用Swarm设计一个Router Agent,根据用户请求内容路由给相应专长的Agent执行,再将结果返回。因为Swarm的无状态和高效特点,特别适合这种“小而多”的代理场景。
- **本地应用插件**:比如做一个本地桌面助手,有多个子Agent:日程Agent管日历提醒,文件Agent管文件搜索等。用Swarm在本地把它们编排起来,互相之间通过函数或消息通信。当用户给总Agent一个指令,总Agent可以根据需要调用不同子Agent完成功能,然后整体返回结果。所有这些都可以在用户电脑上完成,不依赖云端,保障隐私和速度。
- **教学演示**:Swarm因为简洁,也很适合作为**教学用途**来演示多Agent系统的原理。例如学校里用Swarm搭建一个小型的AI协作实例,学生可以清晰地看到Agent是如何传递消息、如何协同解决问题的。这比起一个黑盒的大框架来说,更易于理解学习。
- **适合人群**:OpenAI Swarm面向的是**动手能力强、喜欢轻量框架**的开发者。特别如果你对那些庞大系统有点无从下手,Swarm提供了一种“Return to Basics”的可能:用较低门槛实现自己的多Agent想法。对于追求**高性能和本地运行**的应用开发者,Swarm也很值得一试,因为它减少了一切不必要开销。但是Swarm目前仍在实验阶段,文档和社区资源相对较少,新手可能需要多花些时间摸索。如果希望有完善教程和开箱功能,那么前面介绍的LangChain、AutoGen等可能更适合。
- **常见疑难点**:Swarm虽然轻便,但也意味着很多事情需要开发者自己处理。**上下文管理**就是一例:Swarm本身无状态,如果需要Agent记忆对话历史,必须在代码中自行维护。这对新手来说可能有点挑战,需要设计好每次传给Agent的prompt内容。另一个可能的问题是**功能相对单一**:Swarm的初版主要侧重Agent编排,对于工具接入、知识检索这些高级功能没有现成支持,需要结合其他库(比如LangChain)使用。新手如果贸然上来就用Swarm构建复杂系统,可能会陷入造很多轮子的境地。因此建议先用Swarm实现简单多Agent通讯,把握其精髓,再逐步扩展功能。最后,由于是实验性项目,Swarm可能存在bug或未来接口大改,使用时要做好踩坑和及时跟进更新的心理准备。
**案例:使用Swarm编排两个Agent的简单对话**
我们通过Swarm来实现一个**双Agent分工合作**的小程序:Agent A接收用户请求,然后将请求交给Agent B处理,Agent B用特定格式回复。这样的模式可用于很多场景,比如客服初步接待然后转交专家Agent等。下面是Swarm的代码示例:
```python
!pip install git+https://github.com/openai/swarm.git
from swarm import Swarm, Agent
# 定义Agent B:负责回答问题,每句话不超过10个字
agent_b = Agent(name="Agent B", instructions="请用三句话回答用户问题,每句话不超过10个字。")
# 定义Agent A:负责接收用户消息并交给Agent B处理
def handoff_to_B():
return agent_b
agent_a = Agent(name="Agent A", instructions="你是客服助手,把用户问题转交给Agent B来回答。", functions=[handoff_to_B])
# 创建 Swarm 客户端并运行
client = Swarm()
user_message = {"role": "user", "content": "我想了解一下你们的产品功能。"}
response = client.run(agent=agent_a, messages=[user_message])
print(response.messages[-1]["content"])
```
在这段代码中:
- 我们先定义了 **Agent B**,它的角色是回答用户问题,且需遵守回答格式(3句话,每句不超过10字)。
- 然后定义了 **Agent A**,它的职责仅仅是把用户的请求转交给Agent B处理。我们通过给Agent A指定一个函数 `handoff_to_B` 来实现这一逻辑。这个函数被注册为Agent A可调用的action,当Agent A收到任何消息时就会调用它并返回Agent B,从而将对话交给Agent B继续。
- 创建 Swarm 客户端 `client` 后,我们模拟一个用户消息发送给Agent A,然后使用 `client.run` 来执行对话流程。Swarm框架会让Agent A先处理,该Agent立刻调用 `handoff_to_B` 将控制权给Agent B,Agent B按照自己的instructions生成回复。
- 最终我们打印Agent B的回复内容。
假设Agent B按照要求回复了3句话,每句话不超过10个字,则输出可能类似:
```
"我们的产品功能丰富。
涵盖多种场景。
易于集成使用。"
```
可以看到,通过Swarm,我们用不到20行代码就让两个Agent串联了起来,而且明确限定了各自职责。这种模式如果用LangChain之类也可以做到,但Swarm让过程变得非常直观:定义Agent、编排顺序、运行。对于类似规则明确的多Agent对话,Swarm无疑是种高效解法。当然,这只是冰山一角,更复杂的协作可以扩展这个例子,比如增加更多函数让Agent A根据内容决定交给不同Agent处理等。读者不妨发挥创意,尝试用Swarm实现更多有趣的Agent互动!
---
**结语:**
以上我们介绍了8款在2025年备受关注的AI Agent工具和框架,它们涵盖了从个人开发到企业落地、从单Agent到多Agent协作的各种需求场景。每个框架都有其独特的理念和优势:有的主打模块化和生态(如LangChain),有的突出多智能体协同和代码执行(如AutoGen ),有的强调流程可控(LangGraph)、插件扩展(Semantic Kernel)、角色分工(CrewAI )或轻量编排(OpenAI Swarm )等等。面对琳琅满目的选择,新手可能会问:“**我究竟该学哪一个?**”
其实,大可不必拘泥于选择**唯一**的框架。在实践中,**根据需求灵活组合**才是王道。例如,你完全可以用LangChain管理基础对话和工具调用,再嵌入AutoGen让两个Agent讨论解决某个子问题,最后用Semantic Kernel插件把结果写入数据库。这些框架之间并不冲突,反而可以取长补短。重要的是理解每种框架提供的能力边界,扬长避短地使用它们。
对于初学者,建议**从简单入门**:比如LangChain这种上手快、社区成熟的框架,把基础打牢;然后再逐步尝试高级框架,体验多Agent协同的魅力。阅读官方文档和社区笔记、多跑示例代码是最快的学习方式。遇到问题,多参考我们文中给出的**示例和提示**,相信会少走很多弯路。
AI Agent领域还在飞速发展中,2025年肯定会涌现出更多新奇的工具。不过无论技术如何演进,**让机器更自主、更智能地为人类服务**这一初心不变。希望这篇科普能帮助你对AI Agent有一个全面又生动的了解,激发你的创造灵感。也许下一个令人惊艳的AI Agent应用,就将由你来开发!让我们拭目以待,共同拥抱这个“AI Agent正当时”的时代吧!
**参考资料:**
1. LangChain框架概览 ([开发者必看:10大AI Agent框架全解析(附应用场景+性能对比)_人工智能_和老莫一起学AI-MCP技术社区](https://mcp.csdn.net/6800ab1ba5baf817cf494a85.html#:~:text=1)) ([大模型LangChain框架基础与使用示例-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2331337#:~:text=1.%20%E9%9B%86%E6%88%90%EF%BC%9A%E9%9B%86%E6%88%90%E5%A4%96%E9%83%A8%E6%95%B0%E6%8D%AE%28%E5%A6%82%E6%96%87%E4%BB%B6%E3%80%81%E5%85%B6%E4%BB%96%E5%BA%94%E7%94%A8%E3%80%81API%20%E6%95%B0%E6%8D%AE%E7%AD%89%29%E5%88%B0%20,%E5%8D%8F%E5%8A%A9%E5%86%B3%E5%AE%9A%E4%B8%8B%E4%B8%80%E6%AD%A5%E7%9A%84%E6%93%8D%E4%BD%9C%E3%80%82))
2. AutoGen多Agent协作特点 ([啥是AI Agent!2025年值得推荐入坑AI Agent的五大工具框架!(新手科普篇)-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2487689#:~:text=2%E3%80%81%E6%A1%86%E6%9E%B6%E4%B8%80%EF%BC%9AAutoGen))
3. CrewAI角色扮演式智能体介绍 ([啥是AI Agent!2025年值得推荐入坑AI Agent的五大工具框架!(新手科普篇)-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2487689#:~:text=,%E6%B5%81%E7%A8%8B%E9%A9%B1%E5%8A%A8%EF%BC%9A%E7%9B%AE%E5%89%8D%E4%B8%BB%E8%A6%81%E6%94%AF%E6%8C%81%E9%A1%BA%E5%BA%8F%E4%BB%BB%E5%8A%A1%E6%89%A7%E8%A1%8C%E5%92%8C%E5%B1%82%E7%BA%A7%E6%B5%81%E7%A8%8B%EF%BC%8C%E4%BE%8B%E5%A6%82%E5%9C%A8%E4%B8%80%E4%B8%AA%E9%A1%B9%E7%9B%AE%E7%AE%A1%E7%90%86%E5%9C%BA%E6%99%AF%E4%B8%AD%EF%BC%8C%E4%BB%BB%E5%8A%A1%E5%8F%AF%E4%BB%A5%E6%8C%89%E7%85%A7%E5%85%88%E5%90%8E%E9%A1%BA%E5%BA%8F%E4%BE%9D%E6%AC%A1%E7%94%B1%E4%B8%8D%E5%90%8C%E7%9A%84%E4%BB%A3%E7%90%86%E5%AE%8C%E6%88%90%EF%BC%8C%E5%89%8D%E4%B8%80%E4%B8%AA%E4%BB%BB%E5%8A%A1%E7%9A%84%E8%BE%93%E5%87%BA%E4%BD%9C%E4%B8%BA%E5%90%8E%E4%B8%80%E4%B8%AA%E4%BB%BB%E5%8A%A1%E7%9A%84%E8%BE%93%E5%85%A5))
4. Semantic Kernel插件架构解读 ([Architecting AI Apps with Semantic Kernel | Semantic Kernel](https://devblogs.microsoft.com/semantic-kernel/architecting-ai-apps-with-semantic-kernel/#:~:text=In%20this%20blog%20post%2C%20we%E2%80%99ll,your%20existing%20apps%20and%20services)) ([Architecting AI Apps with Semantic Kernel | Semantic Kernel](https://devblogs.microsoft.com/semantic-kernel/architecting-ai-apps-with-semantic-kernel/#:~:text=Image%3A%20Image%20Semantic%20Kernel%20overview,1))
5. ChatDev开源项目定义 ([GitHub - OpenBMB/ChatDev: Create Customized Software using Natural Language Idea (through LLM-powered Multi-Agent Collaboration)](https://github.com/OpenBMB/ChatDev#:~:text=,designing%2C%20coding%2C%20testing%20and%20documenting)) ([What is ChatDev? | IBM](https://www.ibm.com/think/topics/chatdev#:~:text=ChatDev%20simulates%20a%20virtual%20software,collaboratively%20to%20complete%20each%20phase))
6. LangGraph循环控制对话说明 ([啥是AI Agent!2025年值得推荐入坑AI Agent的五大工具框架!(新手科普篇)-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2487689#:~:text=LangGraph%E6%98%AF%E4%B8%80%E4%B8%AA%E4%B8%93%E6%B3%A8%E4%BA%8E%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E7%9A%84%E6%A1%86%E6%9E%B6%EF%BC%8C%E5%AE%83%E9%80%9A%E8%BF%87%E5%BE%AA%E7%8E%AF%E6%8E%A7%E5%88%B6%E3%80%81%E7%8A%B6%E6%80%81%E7%AE%A1%E7%90%86%E5%92%8C%E4%BA%BA%E6%9C%BA%E4%BA%A4%E4%BA%92%E7%AD%89%E6%8A%80%E6%9C%AF%EF%BC%8C%E5%B8%AE%E5%8A%A9%E5%BC%80%E5%8F%91%E8%80%85%E6%9E%84%E5%BB%BA%E5%A4%8D%E6%9D%82%E7%9A%84AI%20Agent%E3%80%82%E9%80%82%E7%94%A8%E4%BA%8E%E5%A4%9A%E7%A7%8D%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF%EF%BC%8C%E5%A6%82%E6%99%BA%E8%83%BD%E5%AE%A2%E6%9C%8D%E3%80%81%E6%99%BA%E8%83%BD%E6%8A%95%E8%B5%84%E9%A1%BE%E9%97%AE%E7%AD%89%E3%80%82))
7. Phidata功能特性介绍 ([啥是AI Agent!2025年值得推荐入坑AI Agent的五大工具框架!(新手科普篇)-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2487689#:~:text=%E5%AE%83%E6%94%AF%E6%8C%81%E5%A4%9A%E7%A7%8D%E4%B8%BB%E6%B5%81%E7%9A%84%E5%A4%A7%E5%8E%82%E9%97%AD%E6%BA%90%E5%92%8C%E5%BC%80%E6%BA%90LLM%EF%BC%8C%E5%A6%82OpenAI%E3%80%81Anthropic%E3%80%81Cohere%E3%80%81Ollama%E5%92%8CTogether%20AI%E7%AD%89%E3%80%82%E9%80%9A%E8%BF%87%E5%85%B6%E5%AF%B9%E6%95%B0%E6%8D%AE%E5%BA%93%E5%92%8C%E5%90%91%E9%87%8F%E5%AD%98%E5%82%A8%E7%9A%84%E6%94%AF%E6%8C%81%EF%BC%8C%E6%88%91%E4%BB%AC%E5%8F%AF%E4%BB%A5%E8%BD%BB%E6%9D%BE%E5%9C%B0%E5%B0%86AI%E7%B3%BB%E7%BB%9F%E8%BF%9E%E6%8E%A5%E5%88%B0Postgres%E3%80%81PgVector%E3%80%81Pinecone%E3%80%81LanceDb%E7%AD%89%E3%80%82))
8. OpenAI Swarm框架特性 ([啥是AI Agent!2025年值得推荐入坑AI Agent的五大工具框架!(新手科普篇)-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2487689#:~:text=Swarm%E6%98%AFOpenAI%E5%8F%91%E5%B8%83%E7%9A%84%E4%B8%80%E4%B8%AA%E5%AE%9E%E9%AA%8C%E6%80%A7%E5%A4%9A%E6%99%BA%E8%83%BD%E4%BD%93%E7%BC%96%E6%8E%92%E6%A1%86%E6%9E%B6%EF%BC%8C%E6%97%A8%E5%9C%A8%E7%AE%80%E5%8C%96%E5%A4%9A%E6%99%BA%E8%83%BD%E4%BD%93%E7%B3%BB%E7%BB%9F%E7%9A%84%E6%9E%84%E5%BB%BA%E3%80%81%E7%BC%96%E6%8E%92%E5%92%8C%E7%AE%A1%E7%90%86%E3%80%82%E7%94%A8%E4%BA%8E%E5%88%9B%E5%BB%BA%E5%92%8C%E7%AE%A1%E7%90%86%E5%A4%9A%E4%B8%AAAI%20Agent%E3%80%82))
加载中...
正在加载内容...
0
0
评论 (0)
请 登录 后发表评论
暂无评论,来留下第一条评论吧
关于作者
从前慢
已认证用户加入时间: 2025-04-16
攻略数量: 12
相关攻略
🚀 Madechango Club创建筹备会议 🌟
04-30
每天认识一所马来西亚名校——马来西亚排名前30 登嘉楼大学 (Universiti Malaysia Terengganu)
04-30
【Madechango Club创始会员招募公告】 ——与我们一同打造属于留马中国学生的温暖家园
04-30
每天认识一所马来西亚名校——马来西亚排名前30 侯赛因大学 (Universiti Tun Hussein Onn Malaysia)
04-30
每天认识一所马来西亚名校——马来西亚排名前30 吉隆坡大学 (UniKL)
04-30