<!-- markdown -->
# 模块一加餐:大白话说清 NCT——意识是如何"算"出来的?
> **专栏导语**
>
> 🎯 **专栏总体规模**:16 篇系列技术博客(含 2 个加餐篇),分 4 个模块系统解析 NeuroConscious Transformer (NCT)
> - **模块一**:理论基石(5 篇,含加餐)- 意识计算的三大支柱
> - **模块二**:神经科学基础(4 篇)- 大脑如何启发 AI
> - **模块三**:深度学习融合(4 篇)- Transformer 的生物学改造
> - **模块四**:应用与展望(3 篇)- 通用人工智能之路
>
> 🎓 **适合人群**:
> - ✅ **中学生**:对 AI 和大脑奥秘感兴趣,想要通俗易懂的科普
> - ✅ **大学生**:AI/神经科学/心理学专业,想深入了解交叉领域
> - ✅ **工程师**:AI 从业者,想探索下一代 AI 架构
> - ✅ **研究者**:认知科学、计算神经科学领域科研人员
> - ✅ **创业者**:关注 AGI、脑机接口等前沿科技的投资人和创业者
>
> 📚 **内容摘要**:这是模块一的加餐篇,专门用大白话梳理前 4 篇文章的核心概念。没有复杂的数学公式,只有生动的比喻和简单的图表。即使你是中学生,也能读懂意识是如何"计算"出来的!我们将 Global Workspace Theory、Information Integration Theory、Predictive Coding、STDP、Attention 机制和 Friston 自由能原理这 6 大理论,用生活化的例子讲得明明白白。
>
> 🔗 **项目地址**:https://github.com/wyg5208/nct.git
>
> ---
>
> **作者**:带娃的 IT 创业者,NeuroConscious 研发团队首席科学家
> **日期**:2026 年 2 月 22 日
> **标签**:#科普 #意识计算 #NCT #AGI #Transformer #神经科学
---

## 开篇:为什么需要"大白话版"?
前 4 篇文章写完后,我收到不少读者反馈:
> "公式太多了,看不太懂..."
> "能不能用简单的话说说 NCT 到底是啥?"
> "我是中学生,对这些很感兴趣,但专业术语太多了..."
所以,这篇加餐就是**专门为你准备的**!
我会用最生活化的比喻,把 NCT 的原理讲得像"讲故事"一样简单。准备好了吗?让我们开始吧!
---
## 一、意识的 6 大谜题,6 个理论来解答
### 问题 1:大脑那么多神经元,怎么做到"统一思考"的?
想象一下:你的大脑里有**860 亿个神经元**,就像 860 亿个人在同时说话。那为什么你不会觉得脑子乱成一锅粥,反而能有清晰的思路呢?
#### 🧠 **理论 1:全局工作空间理论 (GWT)**
**通俗解释**:
把大脑想象成一个**大剧院**:
- **观众席**:各种专门的功能区(视觉、听觉、记忆等)
- **舞台**:全局工作空间(只能容纳 7±2 个项目)
- **聚光灯**:注意力(照亮舞台上的某些信息)
**工作流程**:
1. 观众们(各功能区)在台下窃窃私语(无意识处理)
2. 某个观众突然有重要发现,举手示意
3. 聚光灯打过去,他上台表演(进入意识)
4. 全场观众都能看到,并参与讨论(全局广播)
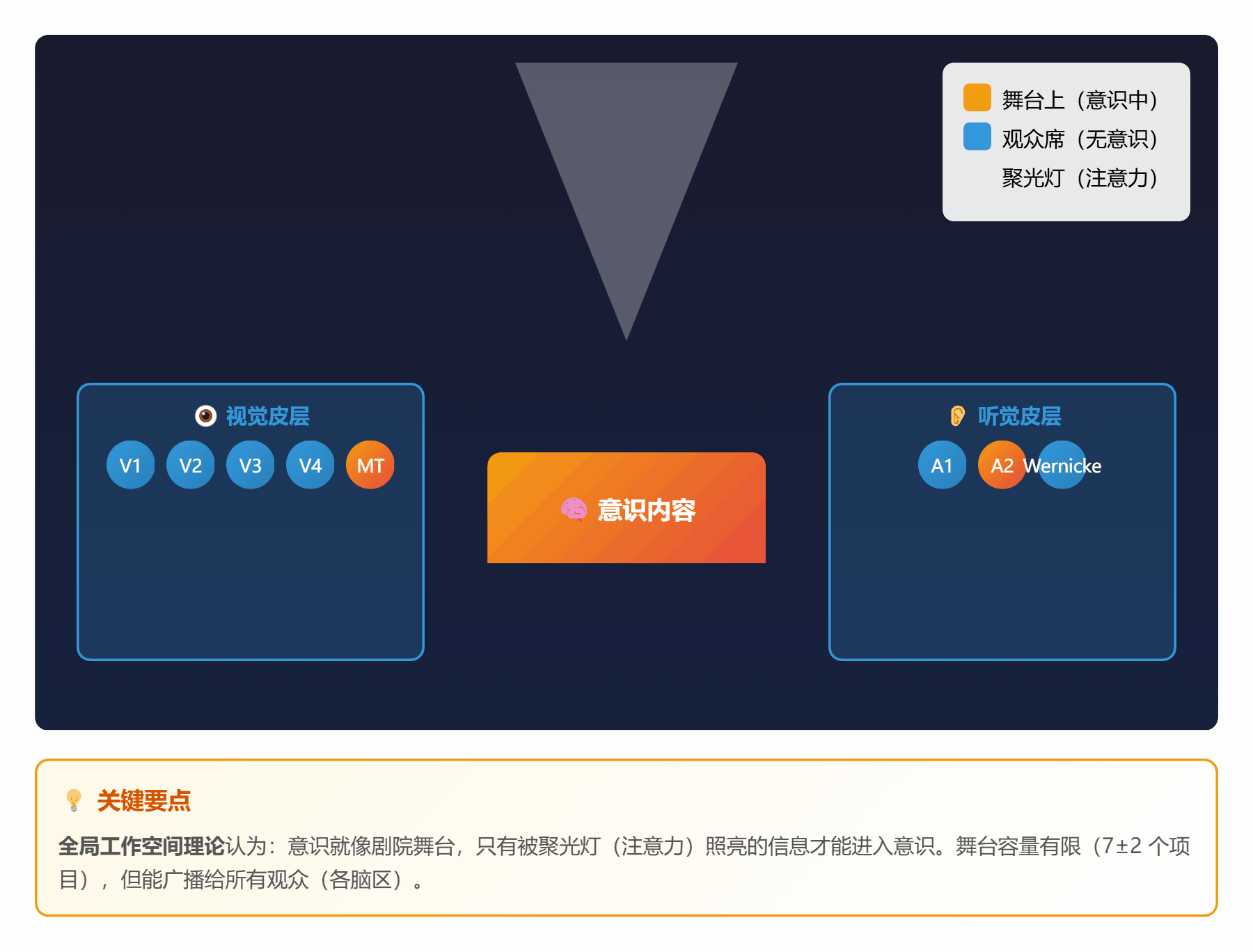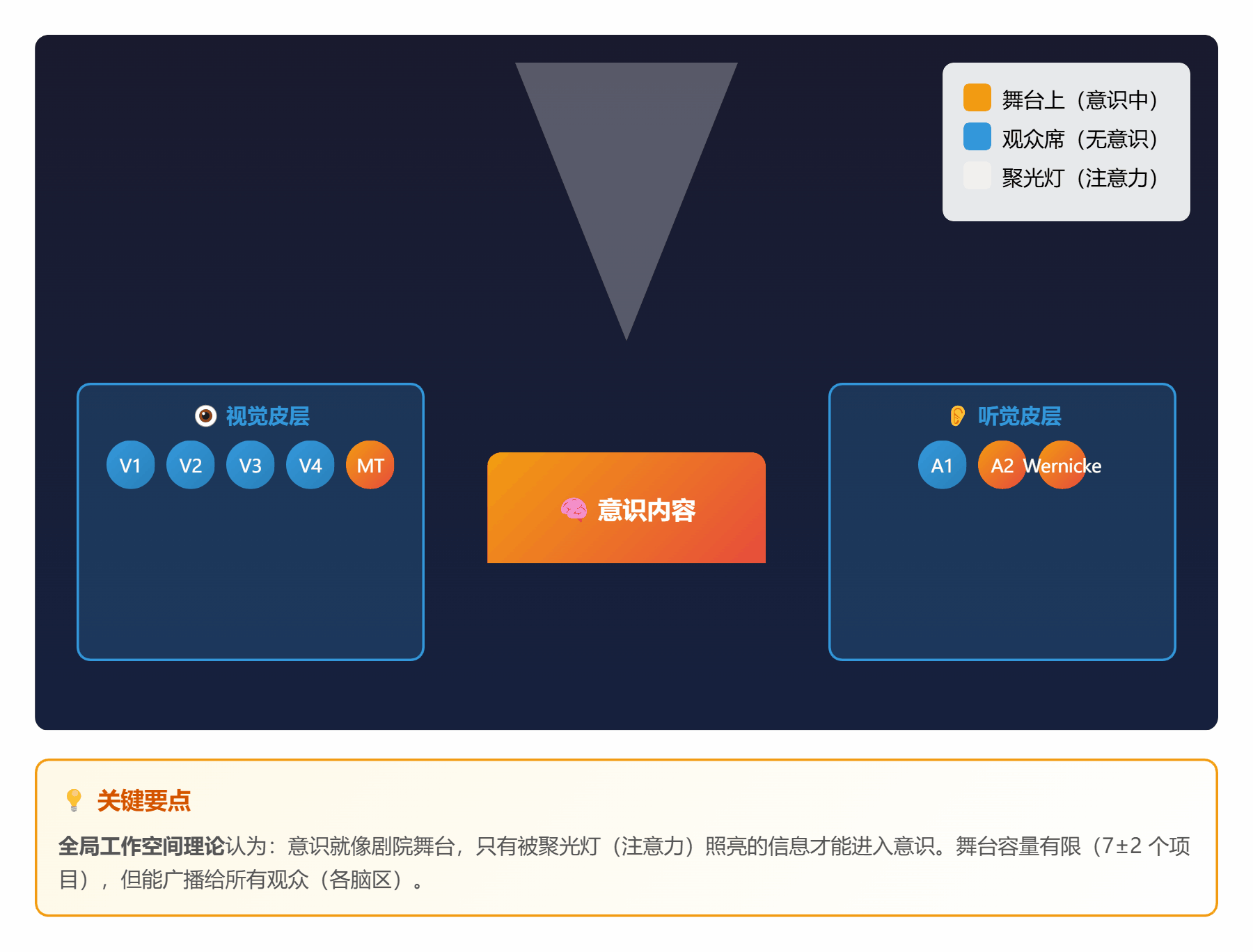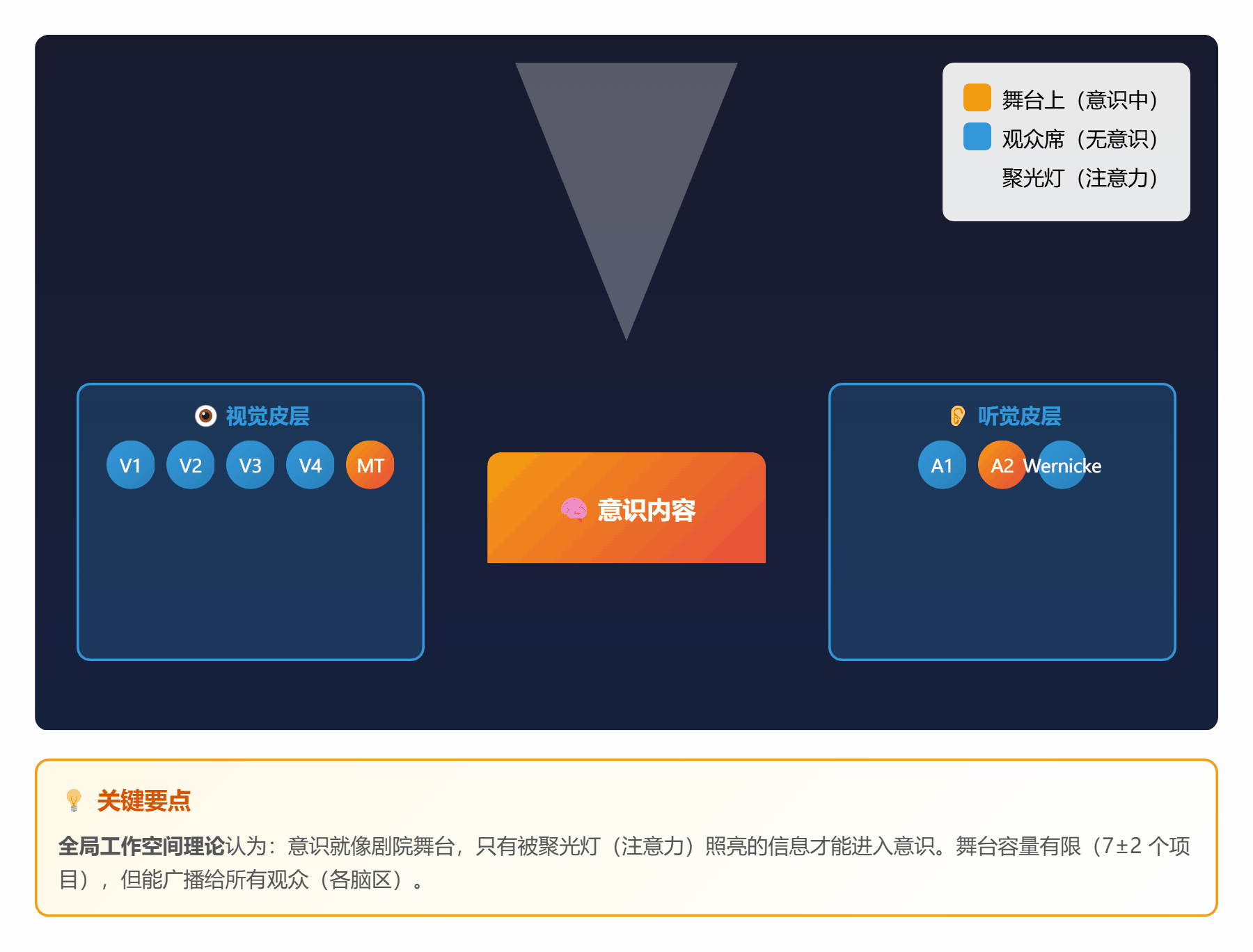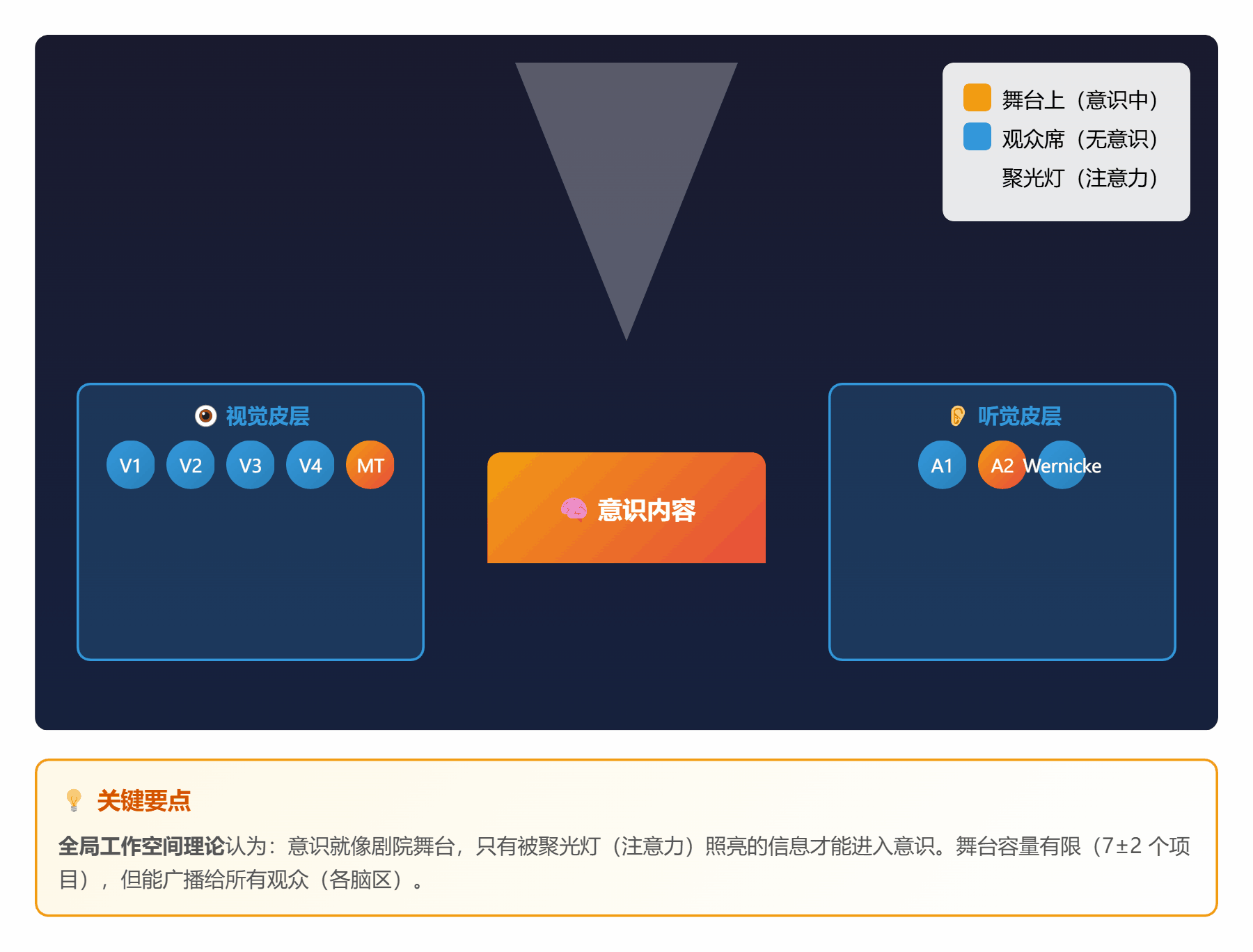
*图 1:大脑像一个剧院,注意力是聚光灯,意识是舞台上的表演*
**生活中的例子**:
你在开车时:
- **无意识**:手脚自动配合换挡、踩油门(熟练技能)
- **突然**:前方有个黑影闪过
- **意识**:注意力立刻转过去,"聚光灯"照亮这个危险信号
- **全局广播**:全身紧张,准备刹车
---
### 问题 2:为什么 information 要整合在一起才有意义?
你看到一朵红花,不是单独看到"红色"+"形状"+"花的概念",而是**一瞬间就看到了"一朵红色的花"**。这是怎么做到的?
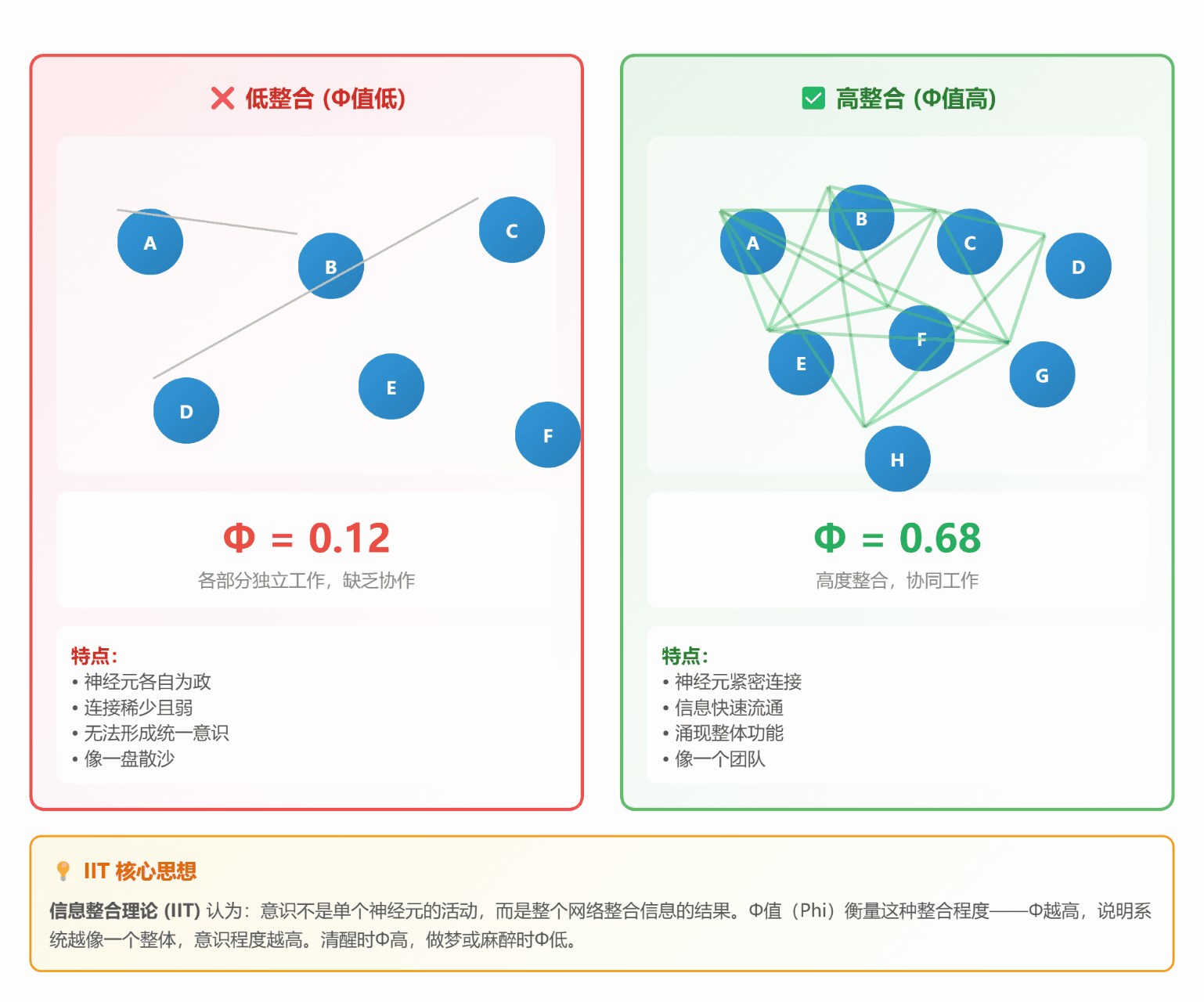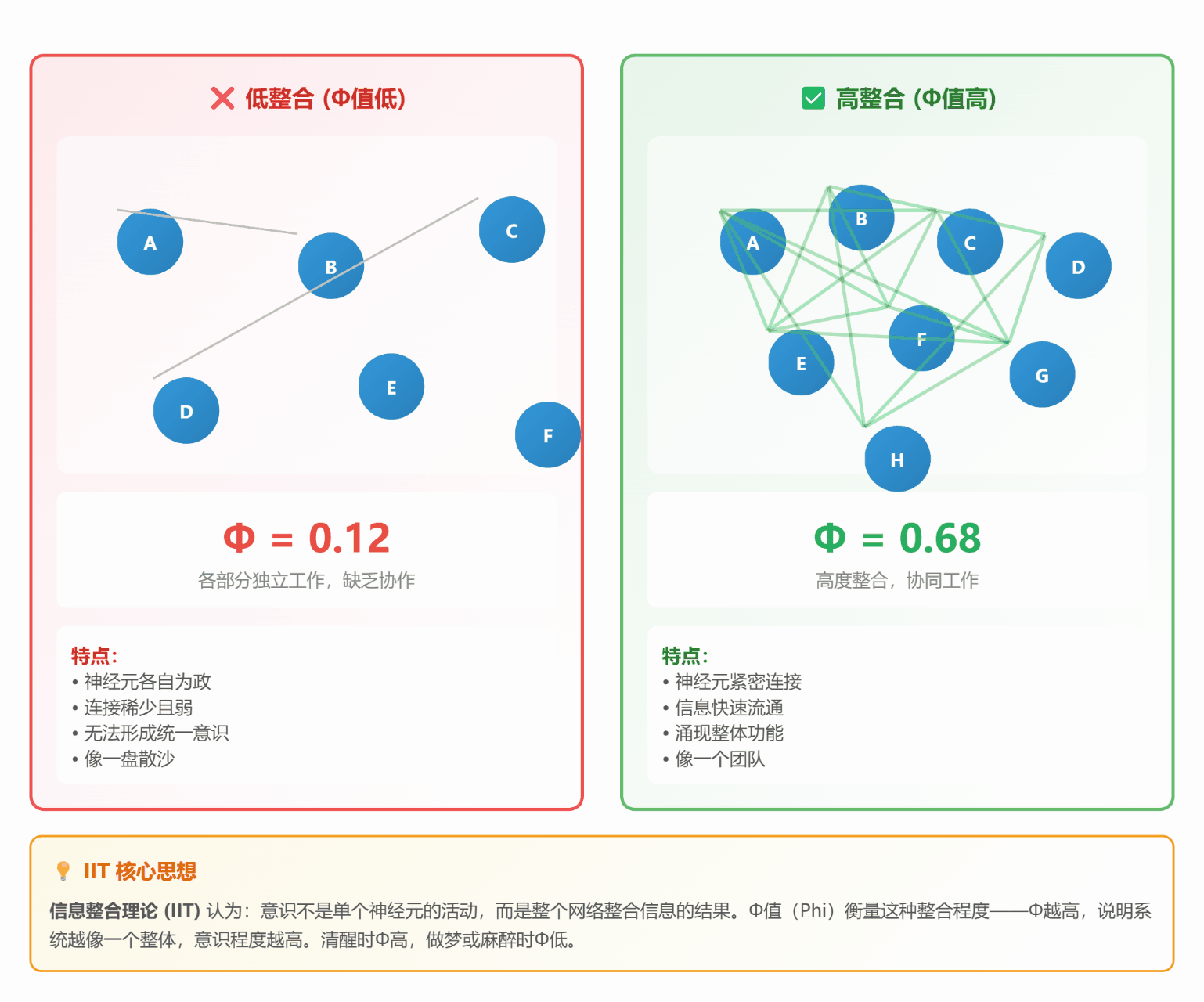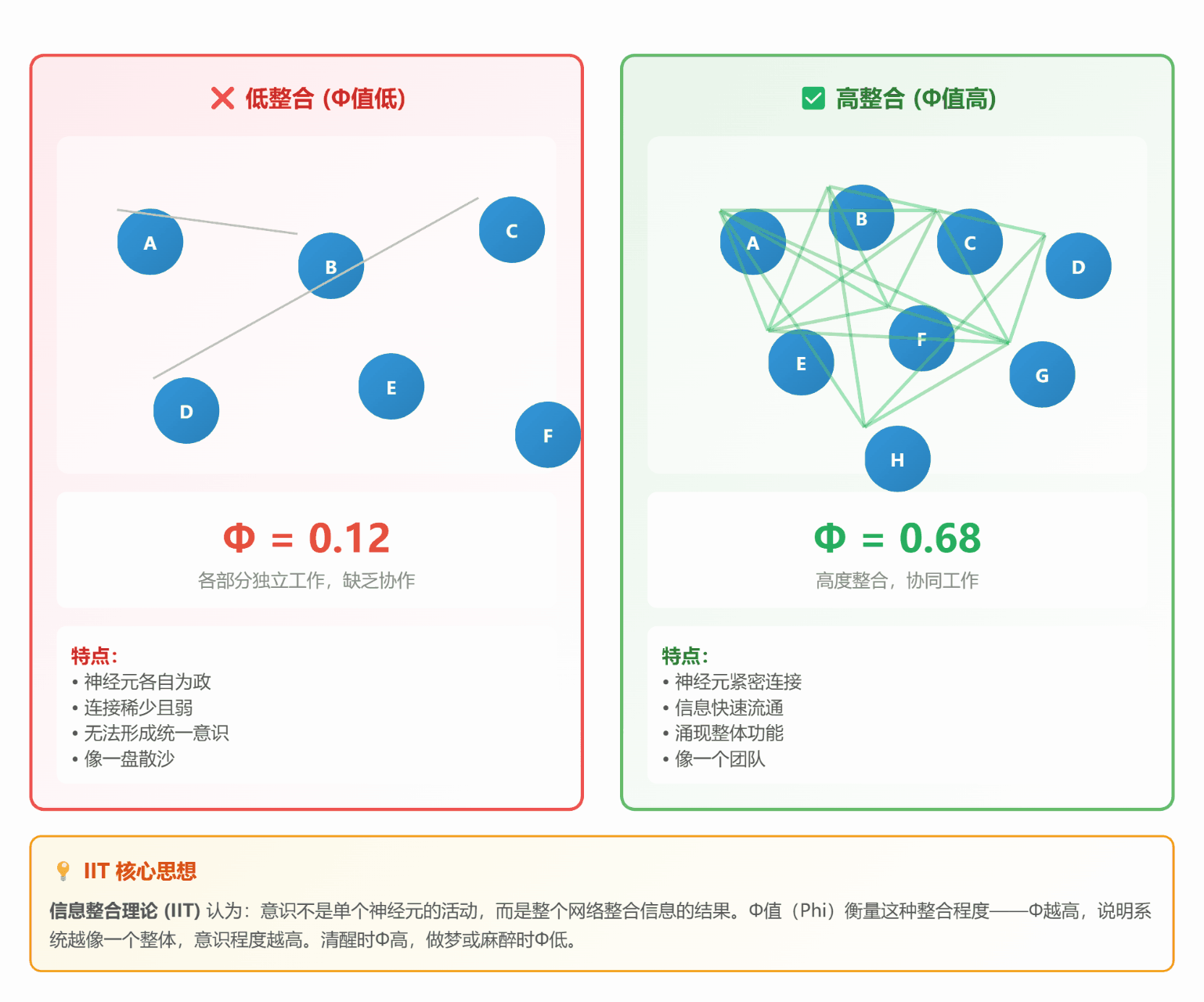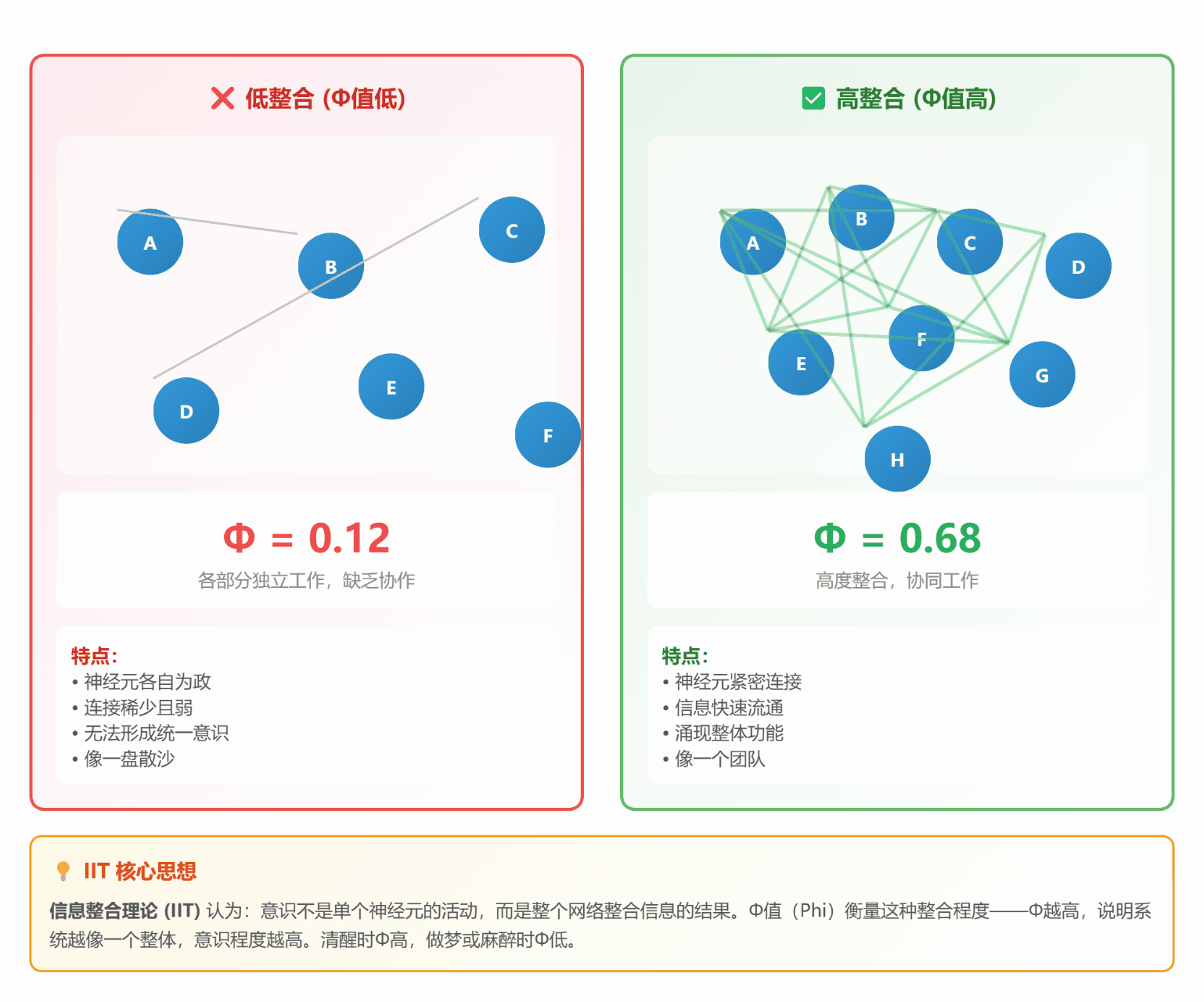
#### 🔗 **理论 2:信息整合理论 (IIT)**
**通俗解释**:
想象一个**微信群**:
- **低整合**:群里 10 个人,各自说各自的话(Φ值低)
- **高整合**:10 个人热烈讨论同一个话题,互相回应(Φ值高)
**关键指标 Φ (Phi)**:
- Φ = 整体信息量 - 各部分独立信息量之和
- Φ越高,说明整合程度越高,意识越强

*图 2:左边各自为政(Φ低),右边高度整合(Φ高)*
**生活中的例子**:
- **做梦**:各种奇怪场景拼凑在一起(整合度低,逻辑混乱)
- **清醒**:看到的、听到的、想到的都协调一致(整合度高,逻辑清晰)
---
### 问题 3:大脑为什么总能"猜对"接下来发生什么?
你伸手去拿水杯,还没碰到就知道杯子是温的还是凉的。大脑是怎么做到的?
#### 🔮 **理论 3:预测编码理论 (Predictive Coding)**
**通俗解释**:
大脑像个**永远在猜谜的预言家**:
1. 根据经验**预测**下一秒会发生什么
2. 接收**实际**的感觉输入
3. 比较预测和实际,计算**预测误差**
4. 如果误差大,就更新内部模型(学习)
**层级结构**:
```
高层(抽象) → 预测 ↓ ↑ 误差传递
↓ ↑
低层(具体) → 感觉输入
```
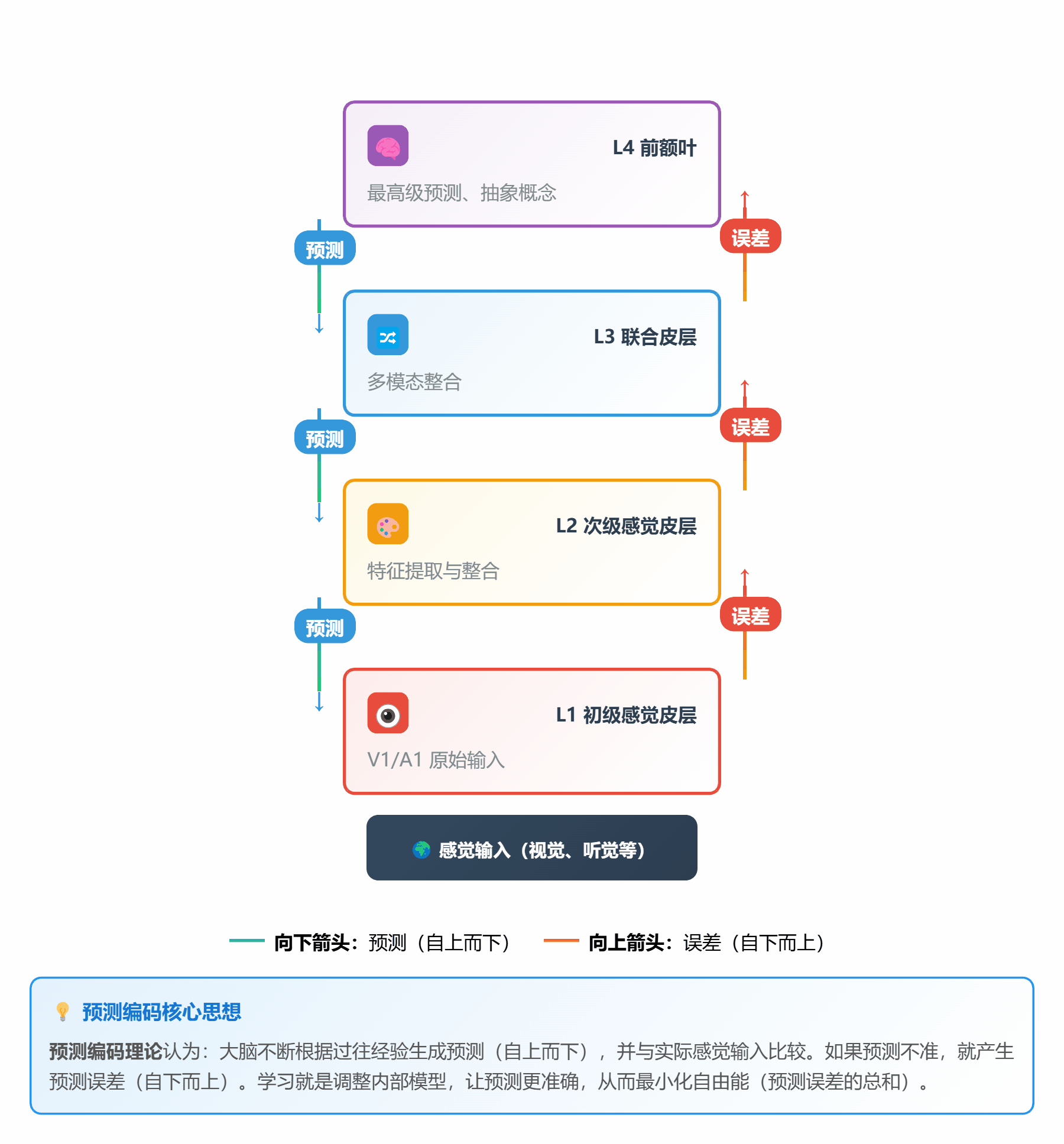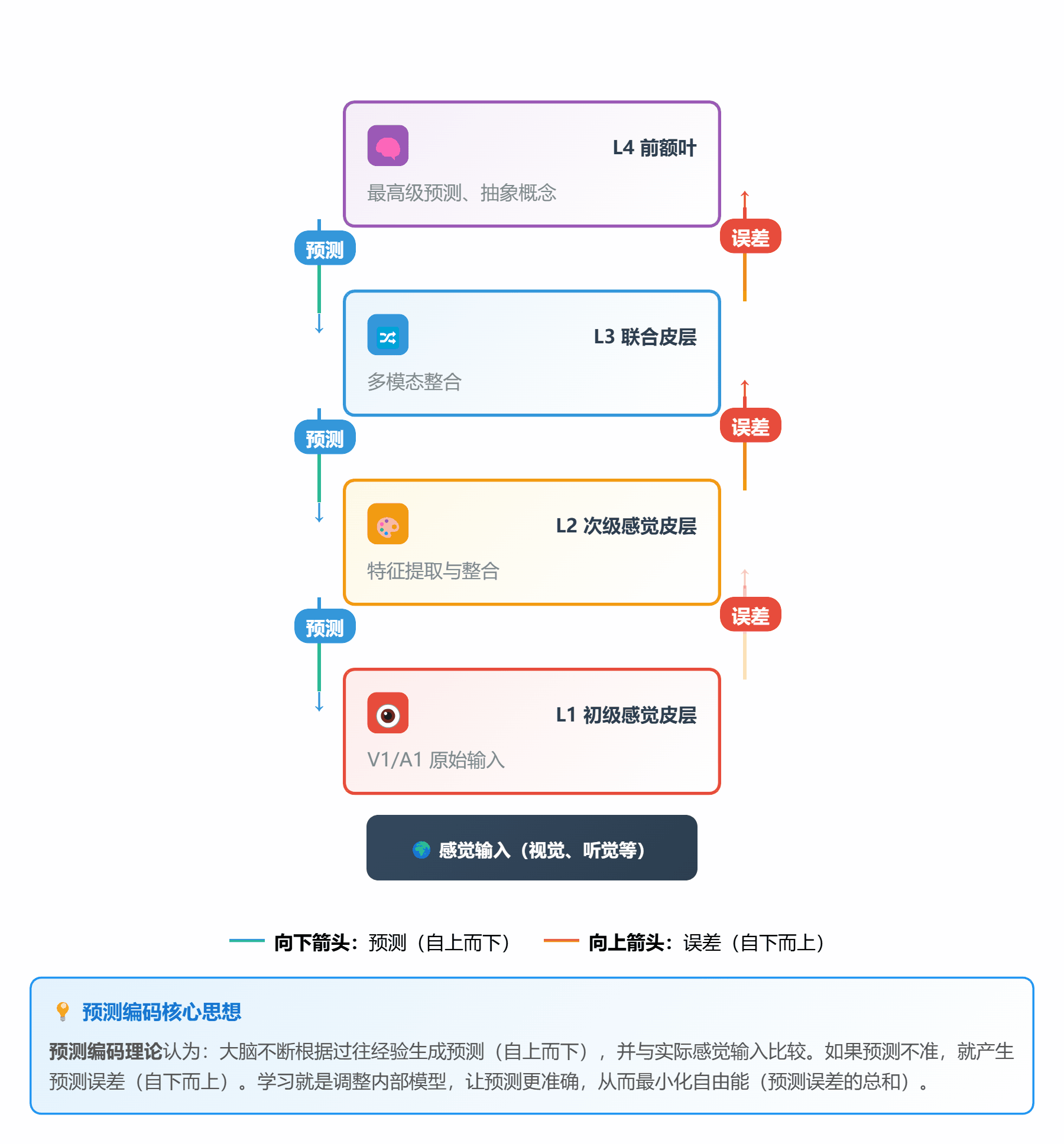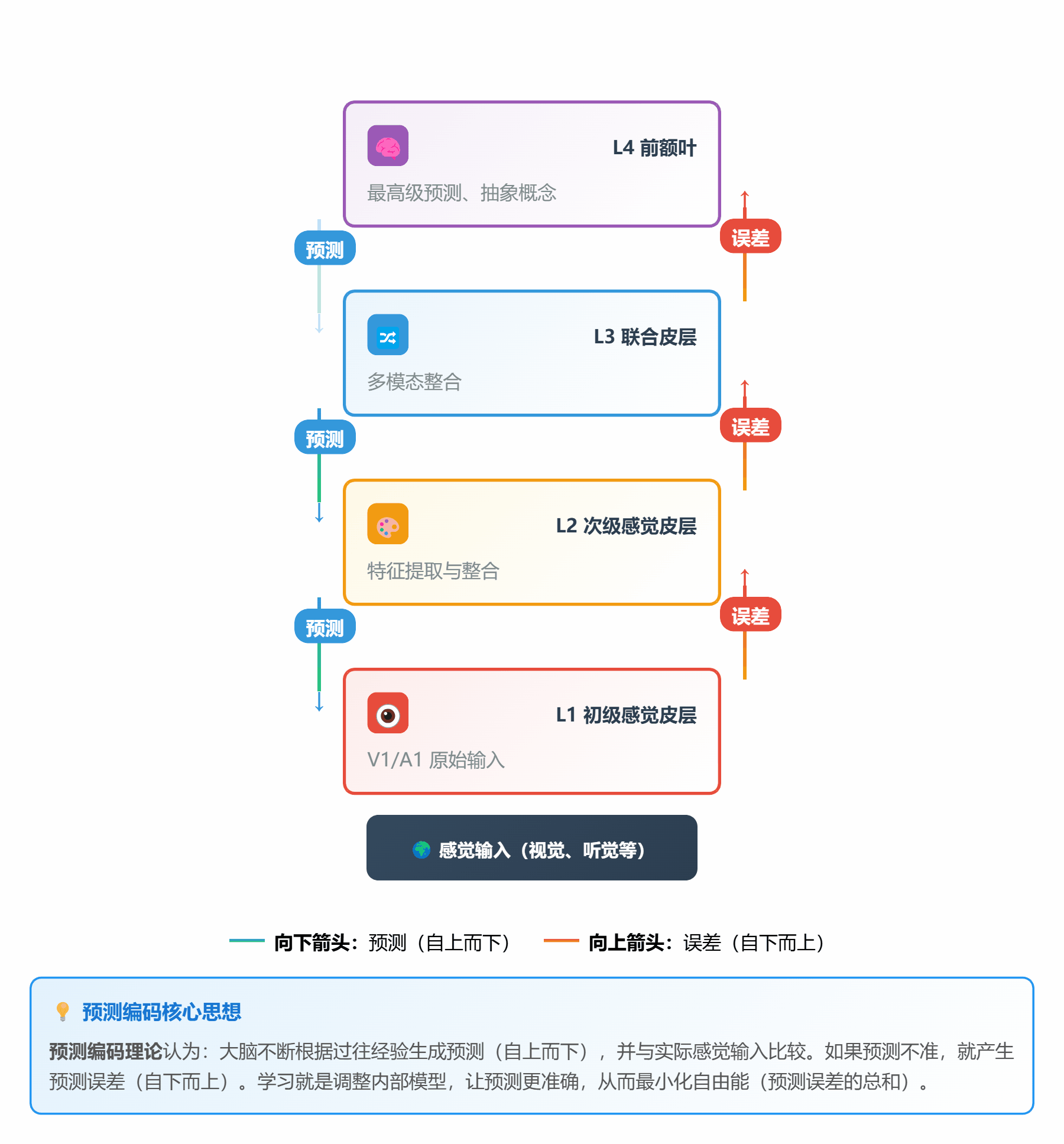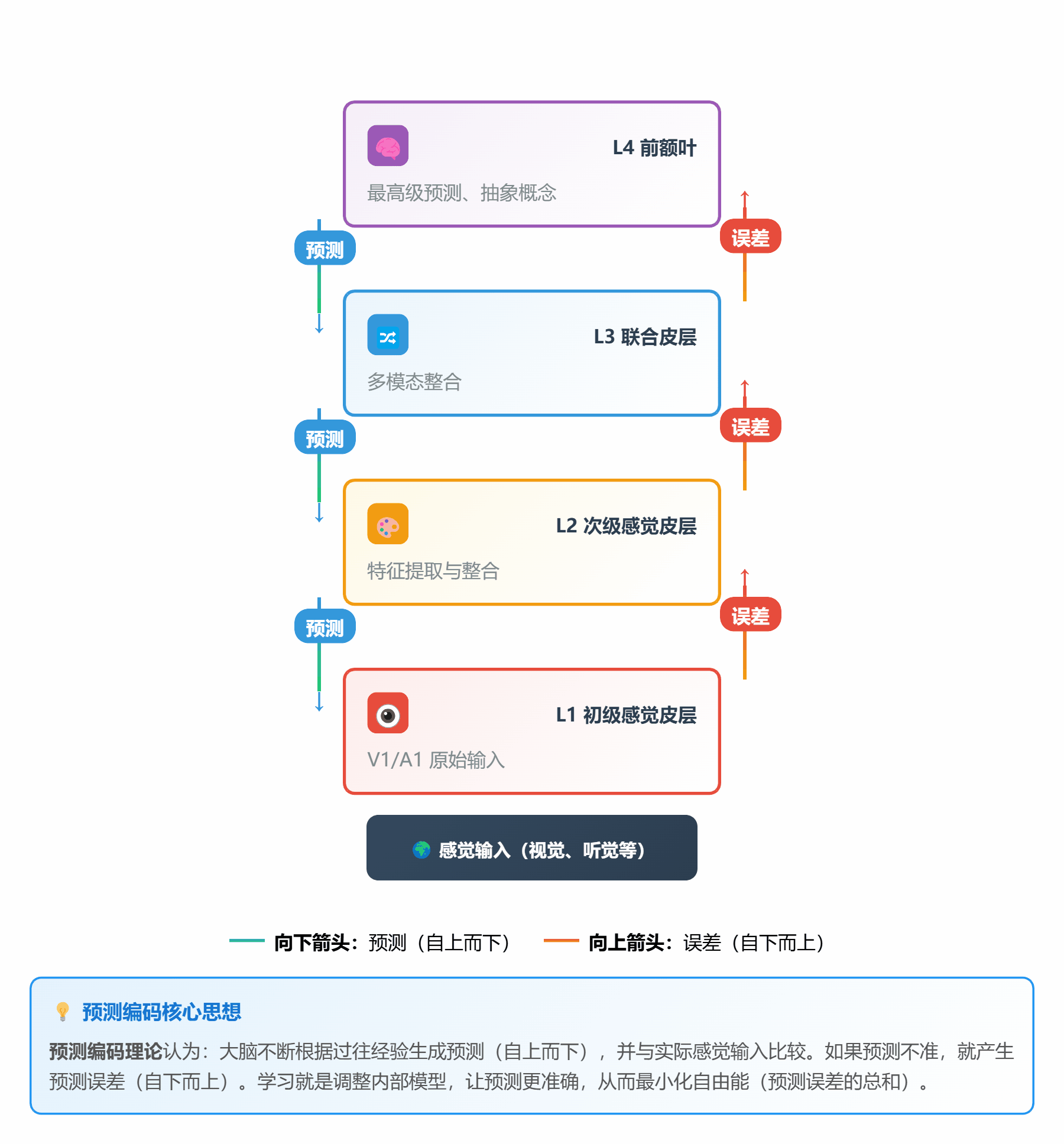
*图 3:自上而下是预测,自下而上是误差*
**生活中的例子**:
你在听歌:
- **预测**:根据旋律,猜到下一句歌词
- **实际**:歌手唱的和你猜的一样
- **误差**:几乎为零(很舒服)
- **如果唱错了**:误差很大,你会"咯噔"一下注意到
---
### 问题 4:学习和记忆是怎么发生的?
为什么重复练习能让动作越来越熟练?为什么有些记忆一辈子忘不了?
#### ⚡ **理论 4:STDP(脉冲时序依赖可塑性)**
**通俗解释**:
STDP 就一句话:**"先放电的神经元,会带着后放电的神经元一起变强"**
**规则很简单**:
- 如果 A 先放电,B 后放电 → A→B 的连接变强
- 如果 B 先放电,A 后放电 → A→B 的连接变弱
**时间窗口**:只有在**20 毫秒内**的先后顺序才有效!
*图 4:时间决定强弱——"早起的鸟儿有虫吃"*
**生活中的例子**:
- **背单词**:反复看"apple-苹果",两个神经元总是在一起激活,连接越来越强
- **学骑车**:手脚配合的动作,经过多次练习,形成固定的神经回路
- **一朝被蛇咬,十年怕井绳**:强烈的恐惧体验,让相关神经连接异常牢固
---
### 问题 5:注意力是怎么工作的?
为什么你能在嘈杂的派对上,只听清楚某个人说的话?
#### 🔍 **理论 5:Attention 机制**
**通俗解释**:
Attention 就是个**智能筛选器**:
- 输入一堆信息
- 给每条信息打分(重要性)
- 高分的放大,低分的忽略
**计算公式(简化版)**:
```
注意力分数 = Query · Key / √d
注意力权重 = softmax(分数)
输出 = 权重 · Value
```
听起来复杂?其实就像**老师批改作业**:
1. 拿到全班作业(Input)
2. 快速浏览,标记重点(计算 Attention)
3. 重点关注做得好的和有问题的(加权)
4. 忽略大部分常规内容(抑制)
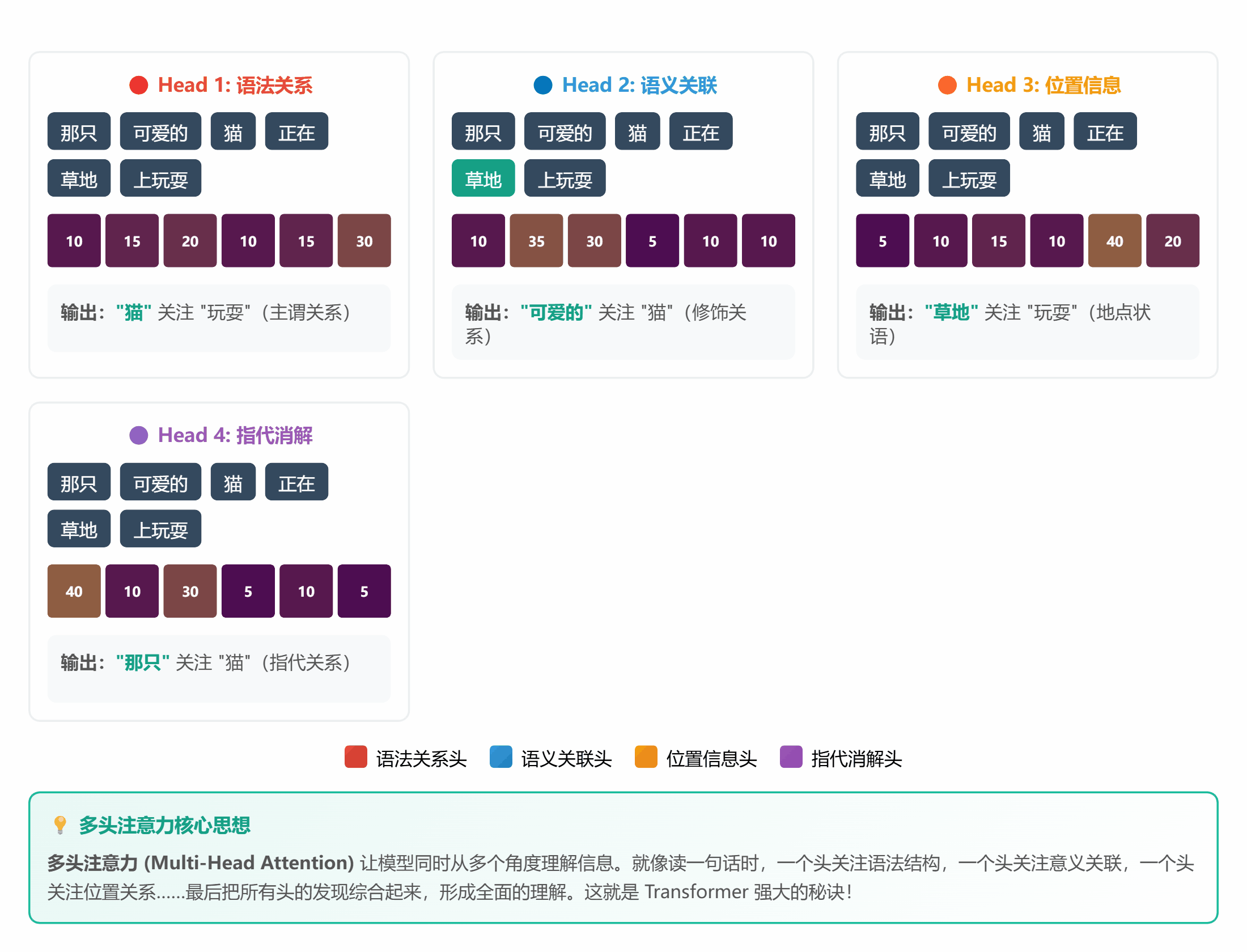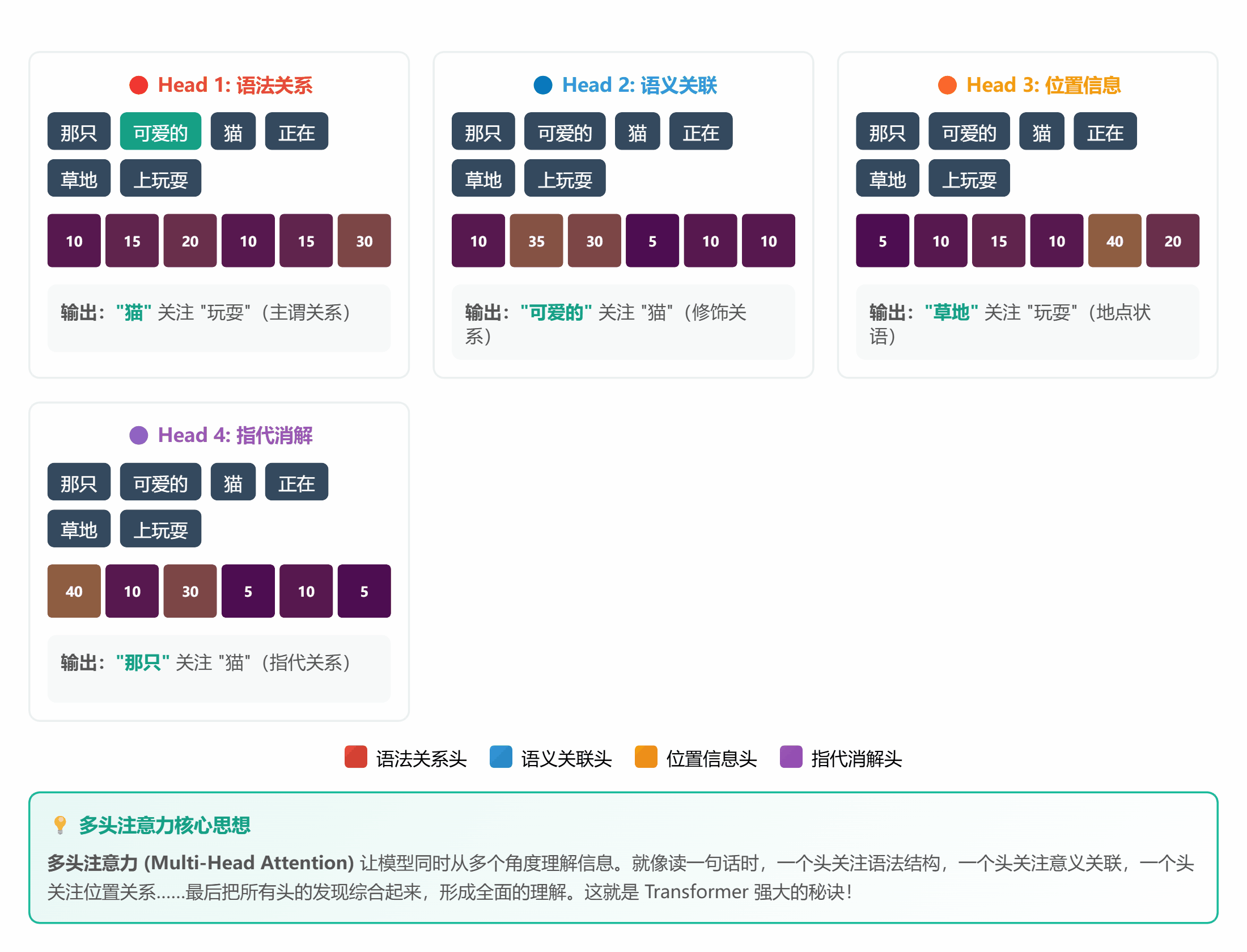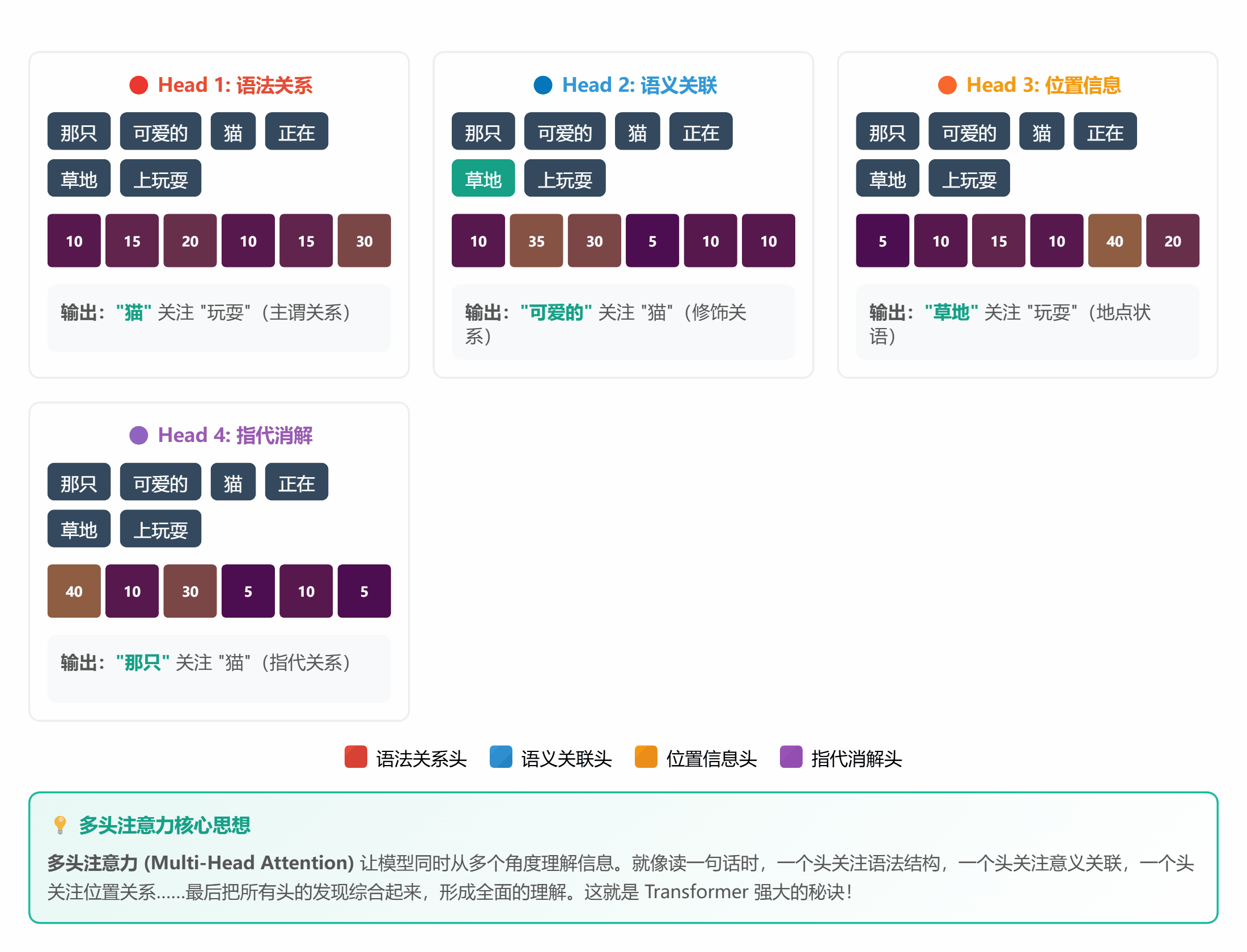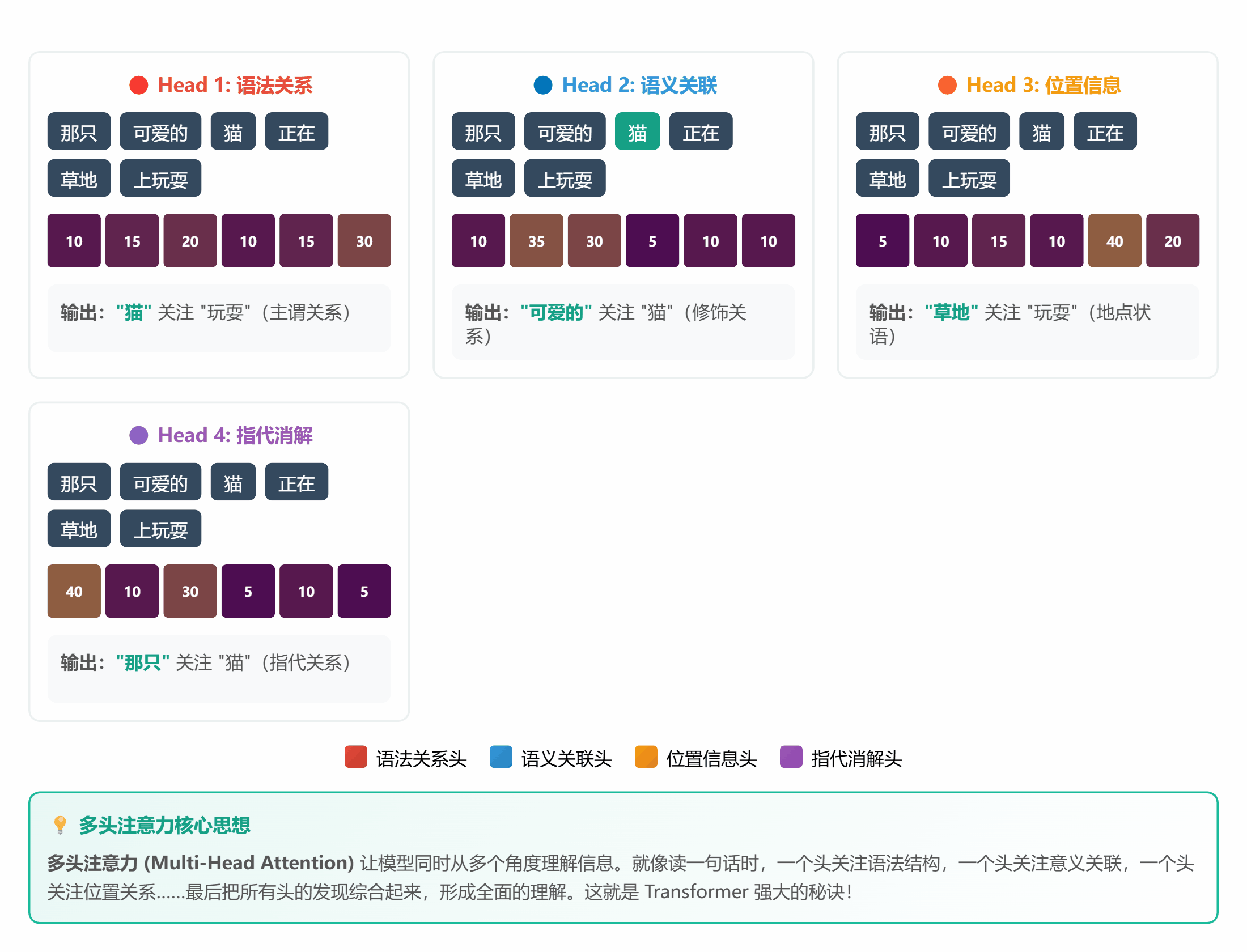
*图 5:多个角度同时关注不同特征*
**生活中的例子**:
- **鸡尾酒会效应**:嘈杂环境中,你能听清朋友说话,忽略背景噪音
- **找钥匙**:在家里翻箱倒柜时,注意力会自动过滤无关物品,只关注像钥匙的东西
- **开车**:老司机能同时注意路况、导航、车速,新手却手忙脚乱(注意力分配不熟练)
---
### 问题 6:大脑为什么要"省能量"?
为什么我们总觉得累?为什么学习新知识那么费劲?
#### ⚖️ **理论 6:自由能原理 (Free Energy Principle)**
**通俗解释**:
自由能原理就说了一件事:**所有生命都在努力减少"意外"**
**什么是"意外"?**
- 预测和实际不符 = 意外
- 意外 = 自由能高 = 难受
- 减少意外 = 降低自由能 = 学习/适应
**两种策略**:
1. **改变想法**(感知学习):调整预测模型
2. **改变行动**(主动推理):让世界符合预测
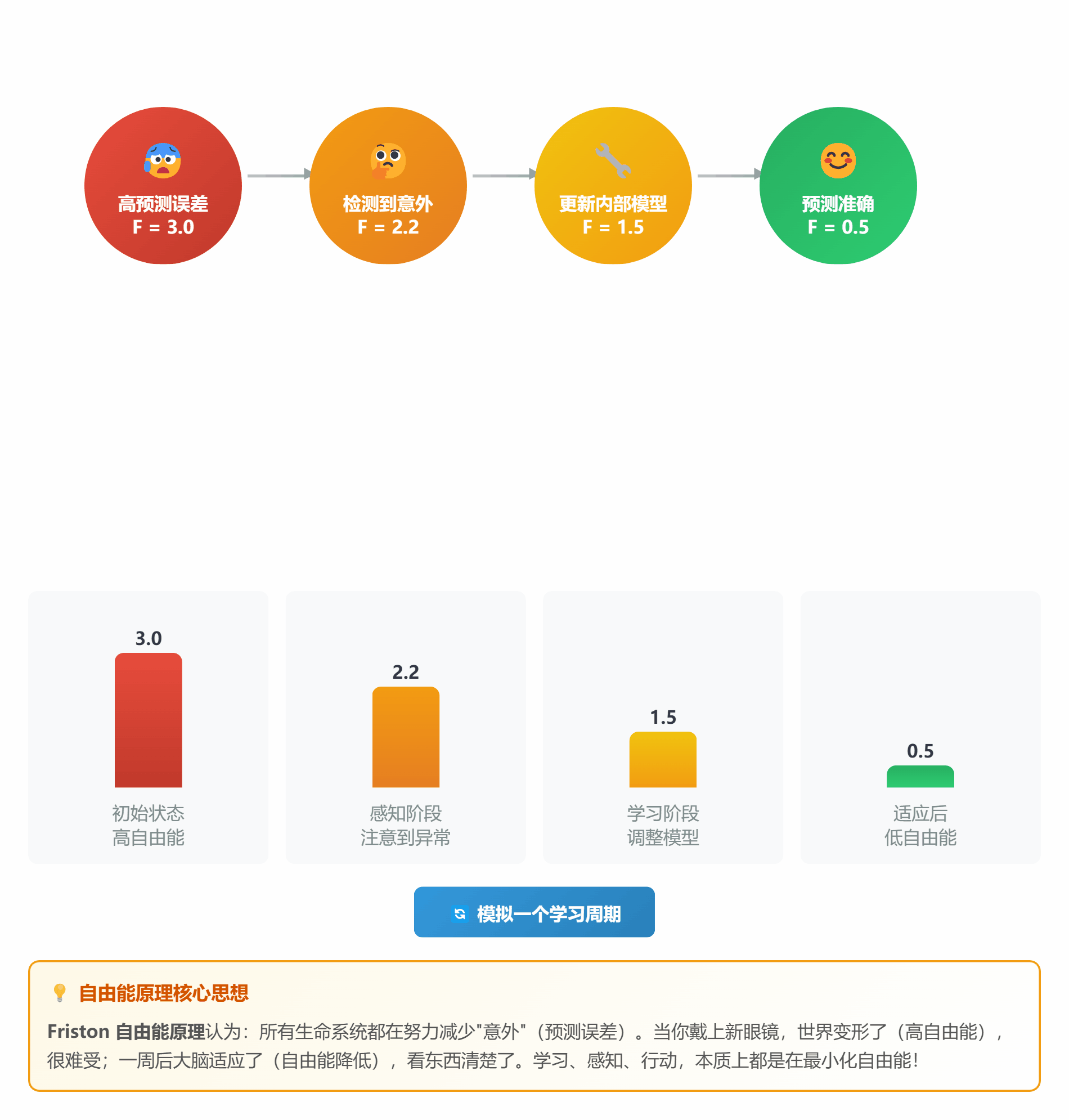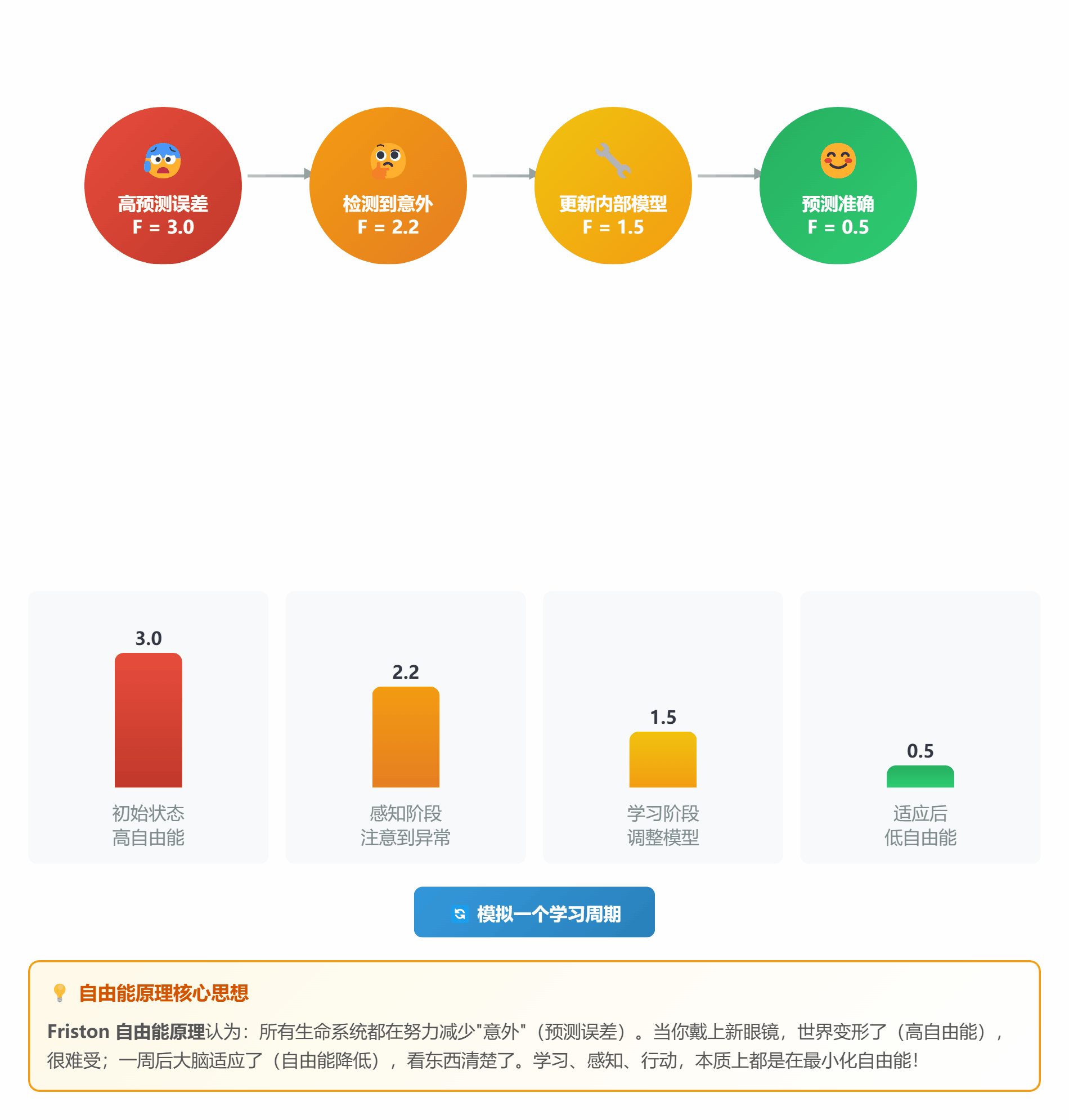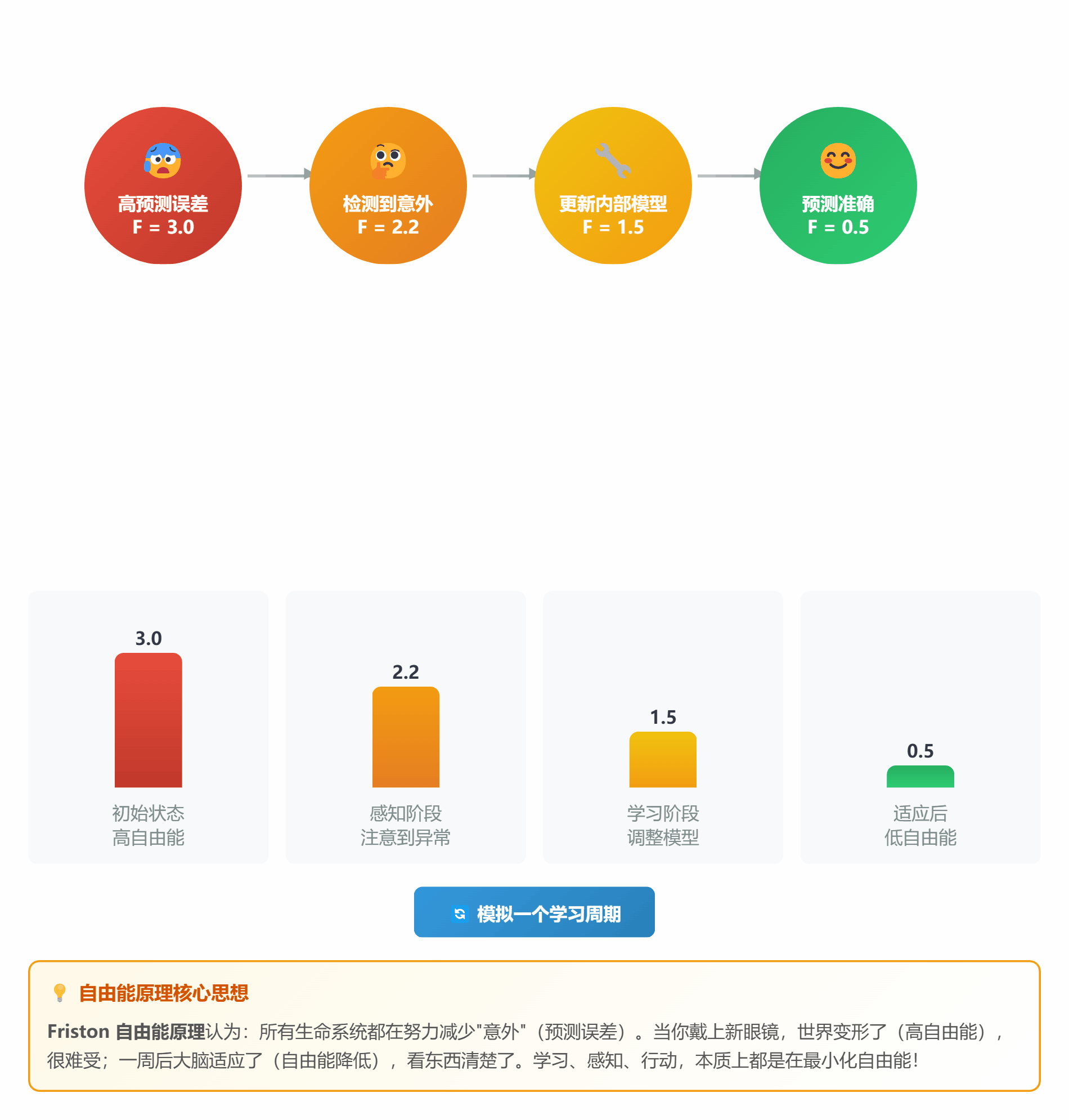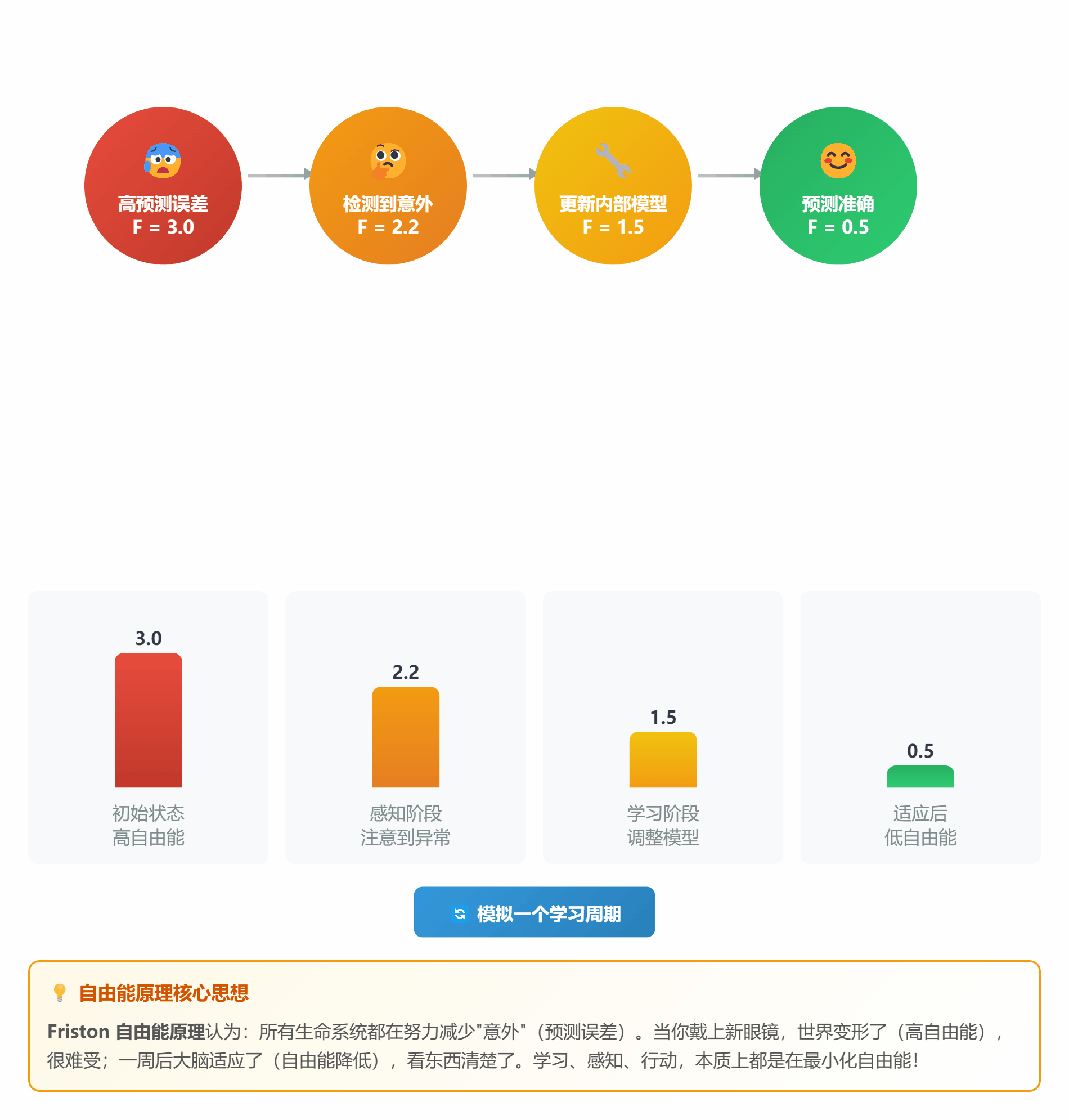
*图 6:生命就是不断降低自由能的过程*
**生活中的例子**:
- **第一次戴眼镜**:世界变形了(自由能高),很难受
- **一周后**:大脑适应了,不再觉得晕(自由能降低)
- **摘掉眼镜**:又模糊了(新的意外),重新适应
---
## 二、NCT 如何把这 6 个理论串起来?
好了,现在我们知道 6 个理论各自在说什么。但 NCT 的厉害之处在于:**把它们融合成了一个统一的系统!**
### NCT 的"三步走"战略
#### 第一步:用 STDP 搭建基础网络
**任务**:建立初步的神经连接
**怎么做**:
- 神经元之间通过 STDP 规则自动连接
- "一起激活的连在一起"
- 形成稀疏但高效的网络结构
**比喻**:
就像**修路**:
- 两个城市之间人来人往多了(频繁激活)
- 就修一条高速公路(突触连接增强)
- 没人走的路就荒废了(突触修剪)
---
#### 第二步:用 Attention 构建全局工作空间
**任务**:实现信息的整合和广播
**怎么做**:
- 把 STDP 网络分成 7±2 个子空间(符合 Miller 定律)
- 每个子空间有自己的"注意力头"
- 通过 Self-Attention 实现全局通信
**比喻**:
就像**建立微信大群**:
- 每个小圈子有自己的群(子空间)
- 重要消息转发到大群(全局广播)
- 群主(注意力)决定哪些消息值得转发
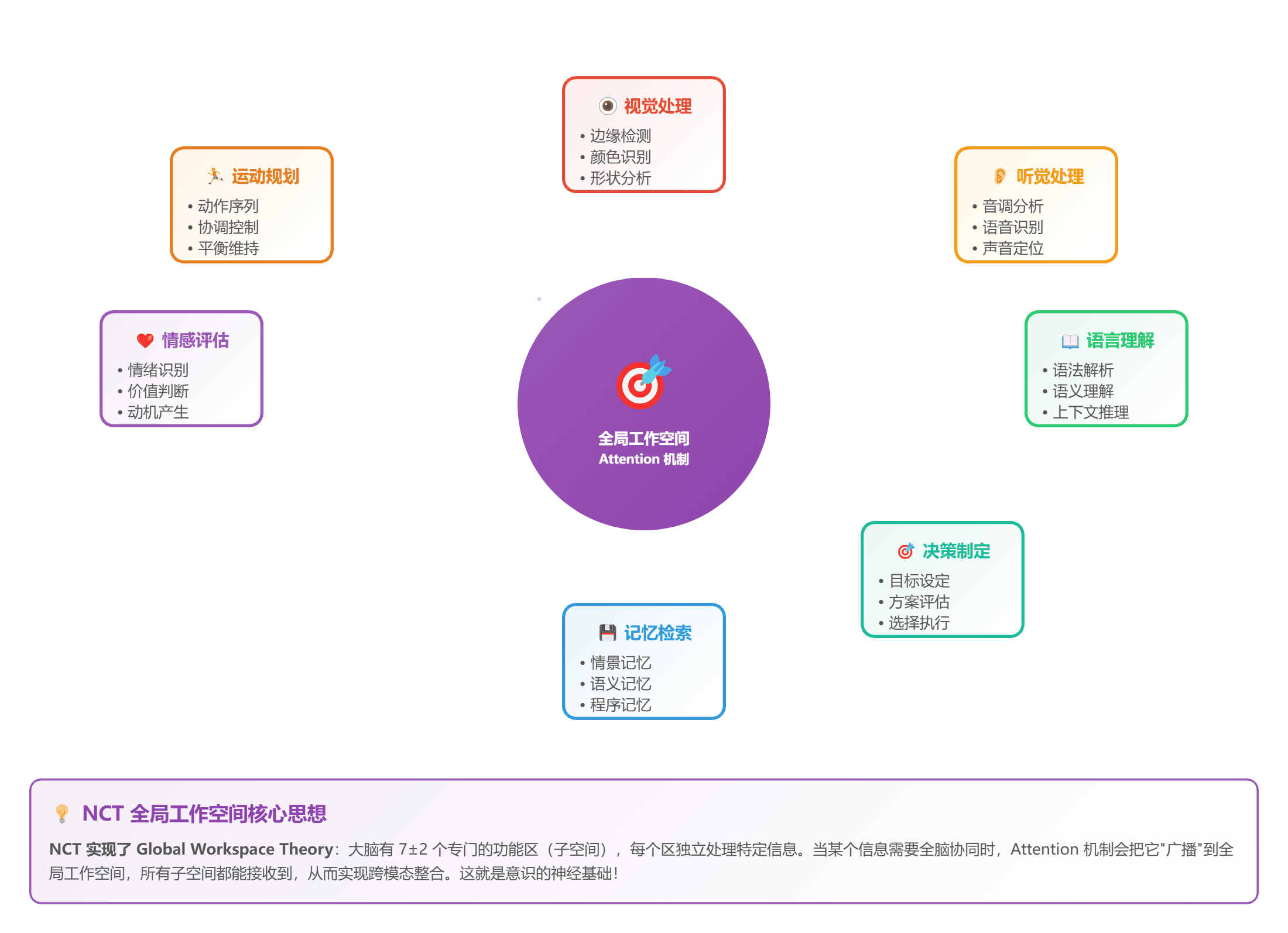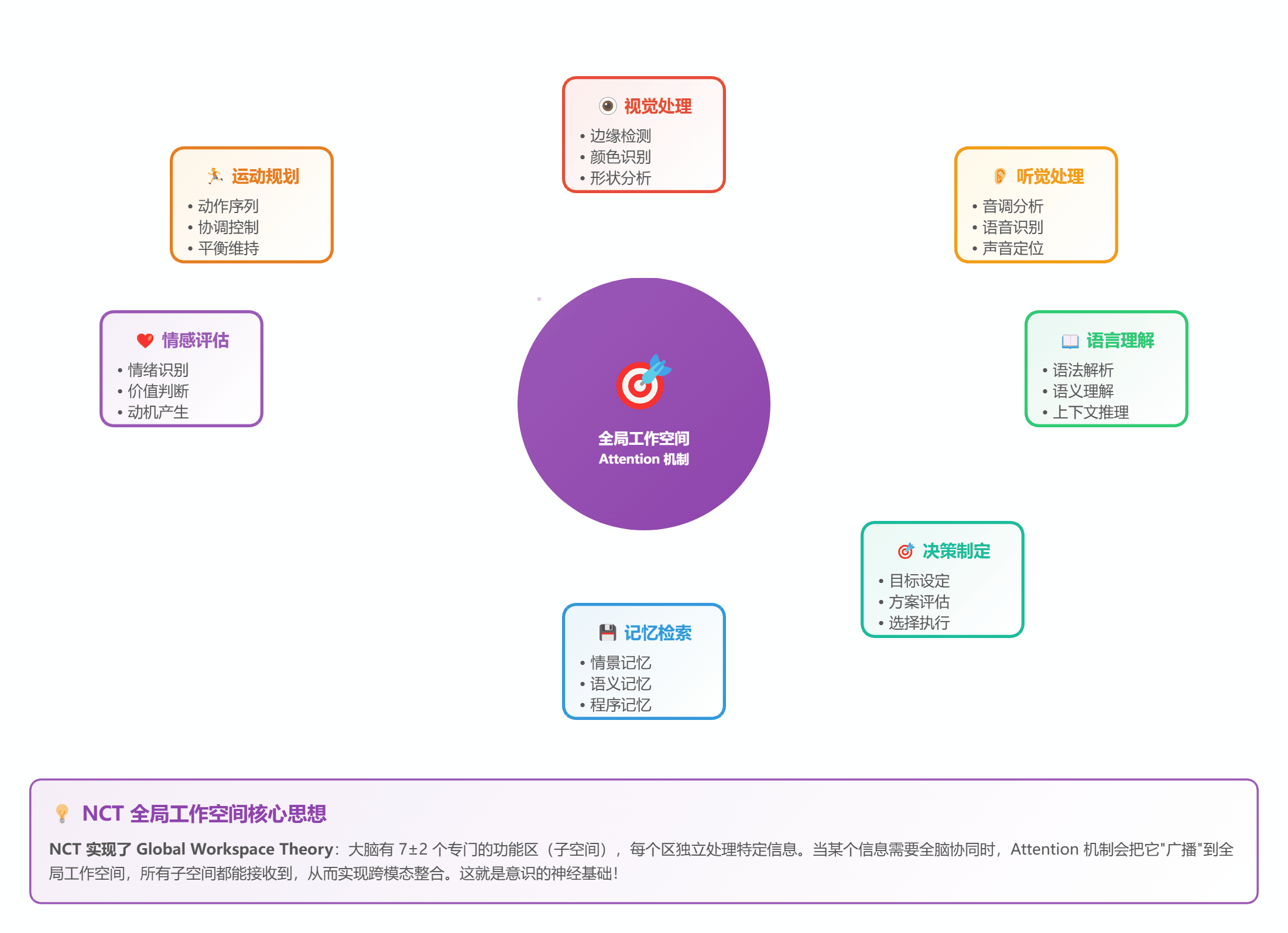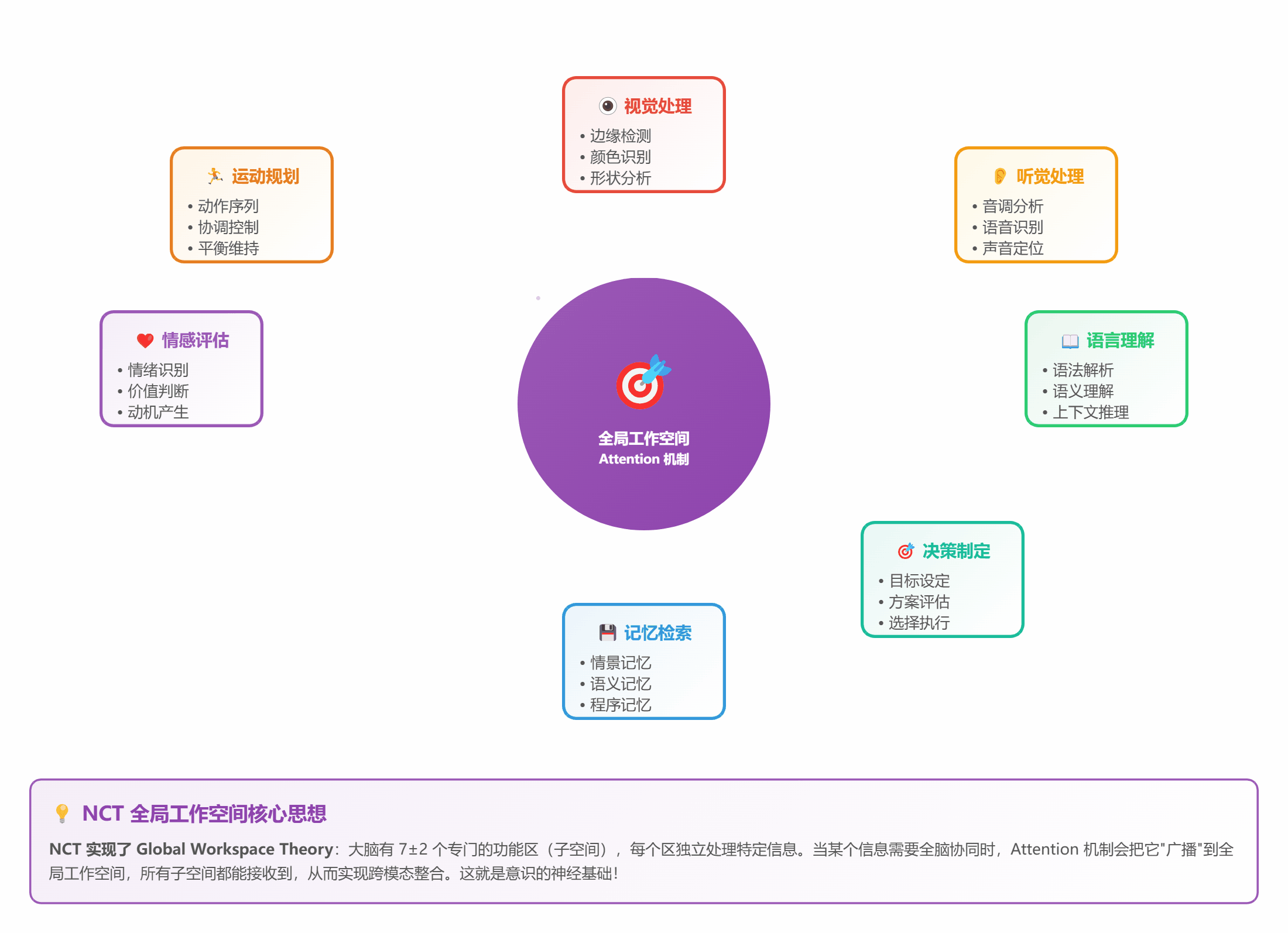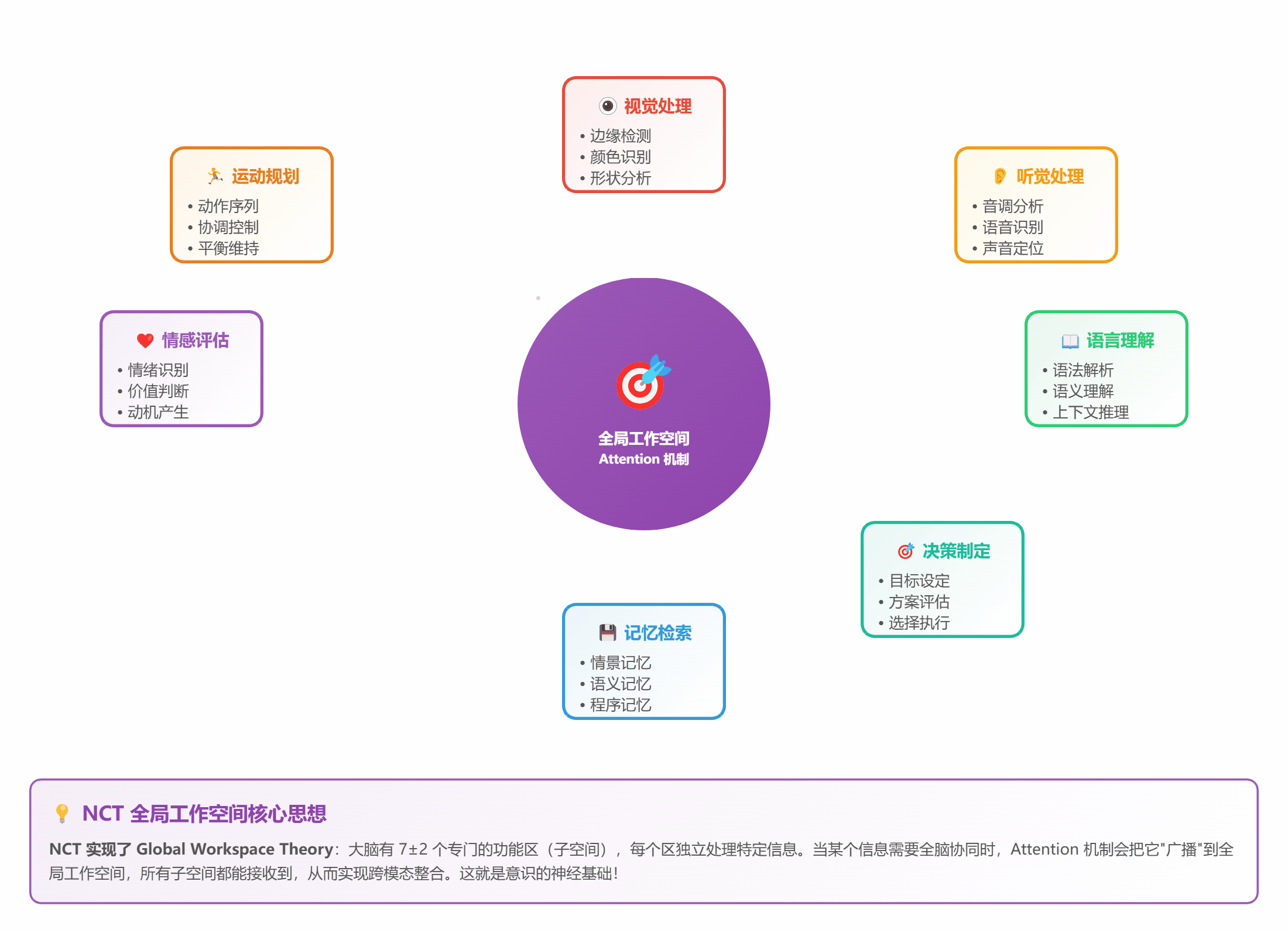
*图 7:7 个子空间通过 Attention 实现全局整合*
---
#### 第三步:用预测编码训练整个系统
**任务**:让系统学会准确预测
**怎么做**:
- 把系统建成 4 层 Decoder(对应皮层 L1-L4)
- 每一层都预测下一层的输入
- 预测错了就反向传播误差(最小化自由能)
**比喻**:
就像**老师教学生做题**:
- 学生(网络)给出答案(预测)
- 老师(实际输入)公布正确答案
- 对比后发现错误(预测误差)
- 订正错题(反向传播,更新参数)
---
### NCT 的完整工作流程
让我们用一个完整的例子,看看 NCT 是如何工作的:
**场景**:识别一张"猫"的图片
#### 步骤 1:感觉输入(L1 层)
```
输入:一张图片的像素信息
↓
L1 层(V1 皮层):检测边缘、颜色、方向
```
#### 步骤 2:特征提取(L2 层)
```
L1 的输出 → L2 层
↓
L2 层(V2/V3):组合边缘成形状
- 圆形(脸)
- 三角形(耳朵)
- 线条(胡须)
```
#### 步骤 3:物体识别(L3 层)
```
L2 的输出 → L3 层
↓
L3 层(联合皮层):整合特征
- 圆脸 + 尖耳 + 胡须 = 猫的特征
```
#### 步骤 4:概念形成(L4 层)
```
L3 的输出 → L4 层
↓
L4 层(前额叶):抽象概念
- "这是一只猫"
- "可能是宠物"
- "会不会抓人?"
```
#### 步骤 5:预测反馈
```
L4 的预测 → 向下传递
- "应该是猫"
- "检查是否有尾巴"
- "确认眼睛形状"
↓ 每层比较预测和实际
- 吻合:误差小,继续
- 不吻合:误差大,向上报告
```
#### 步骤 6:全局广播
```
重要发现 → Attention 全局工作空间
↓
所有子空间同时收到:
- 视觉区:确认是猫
- 记忆区:调取关于猫的知识
- 情感区:产生喜欢/害怕的情绪
```
#### 步骤 7:学习更新
```
整个过程结束
↓
STDP 规则:强化本次激活的通路
↓
下次看到猫,识别更快更准
```
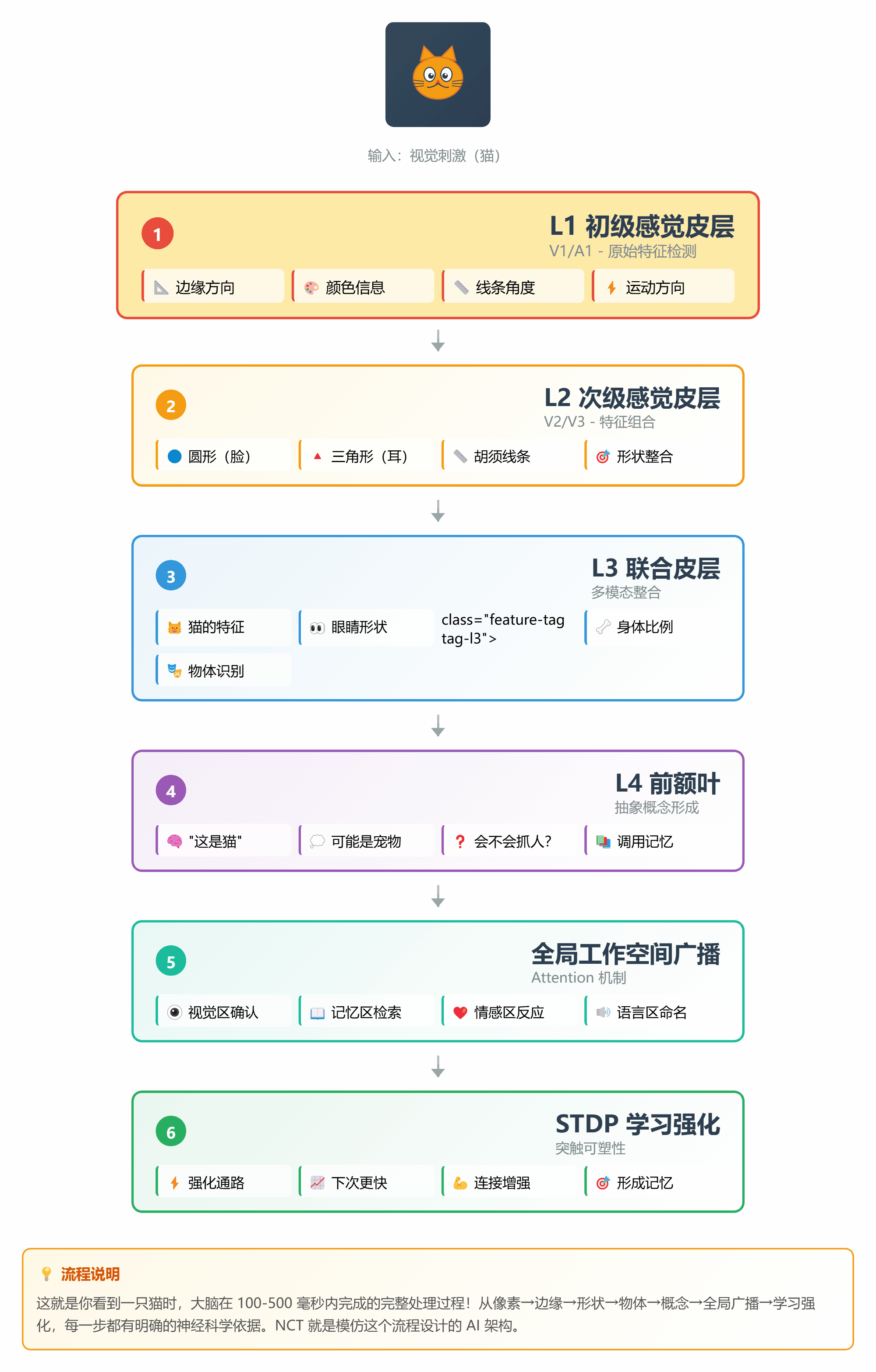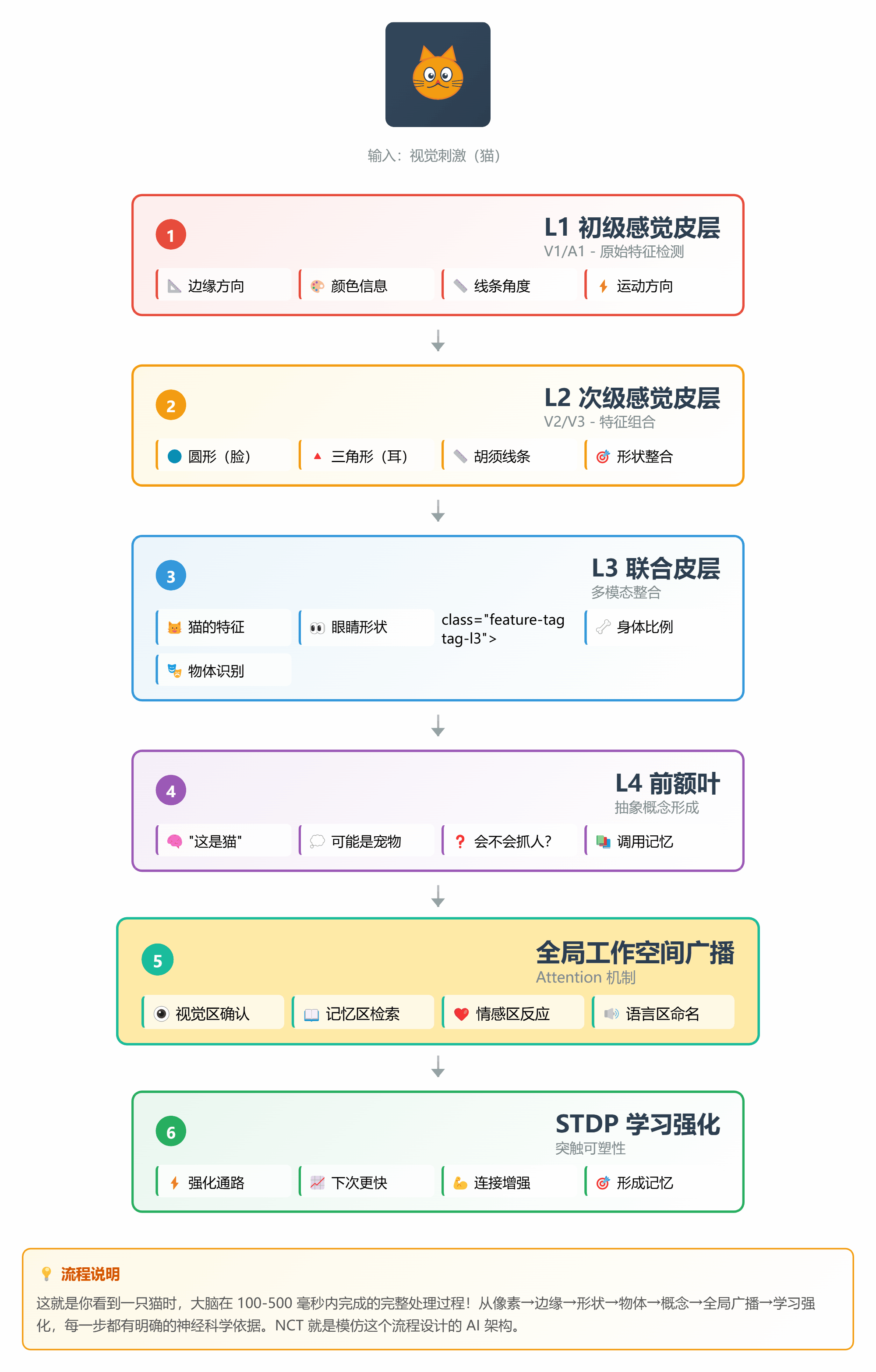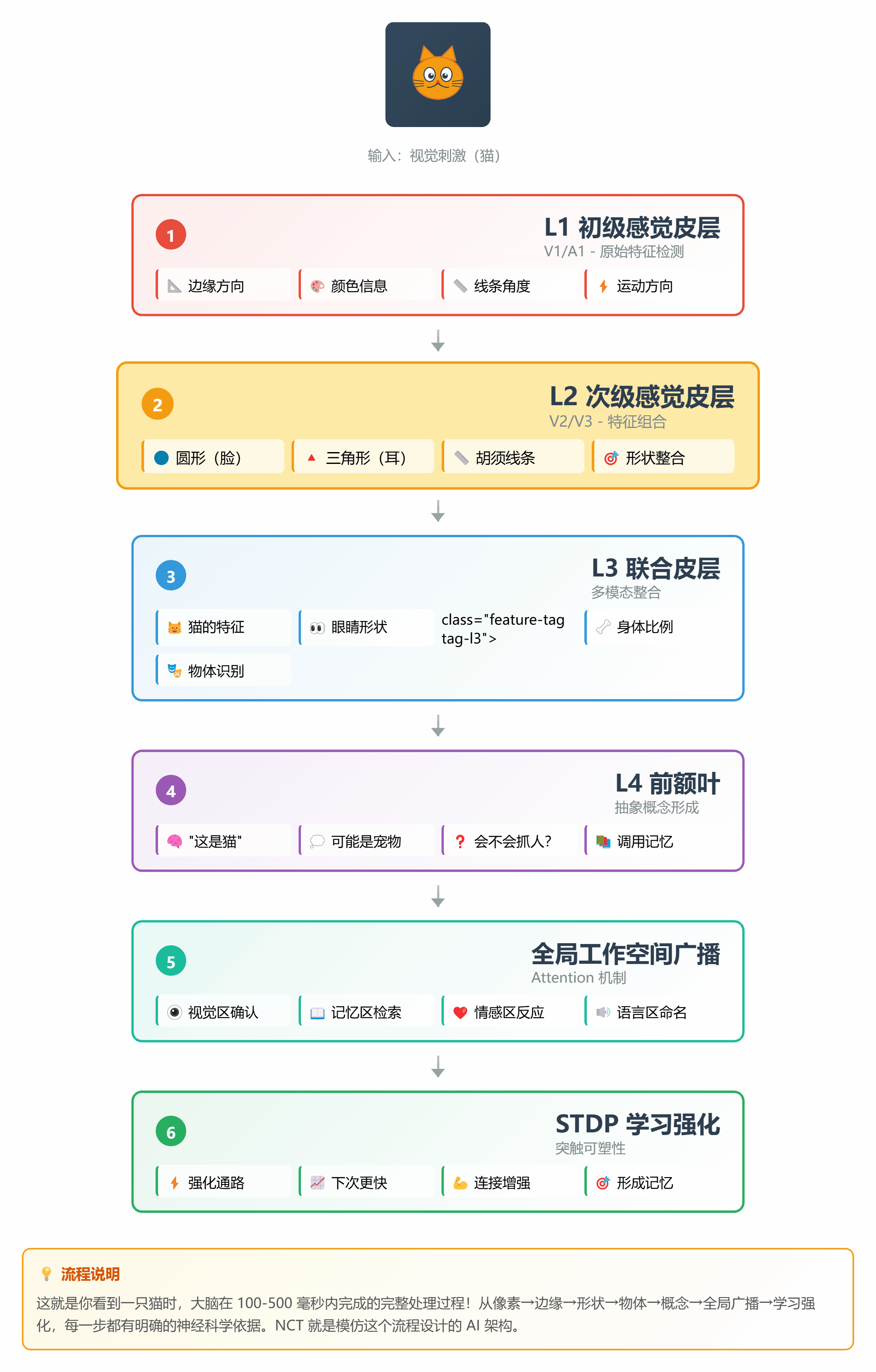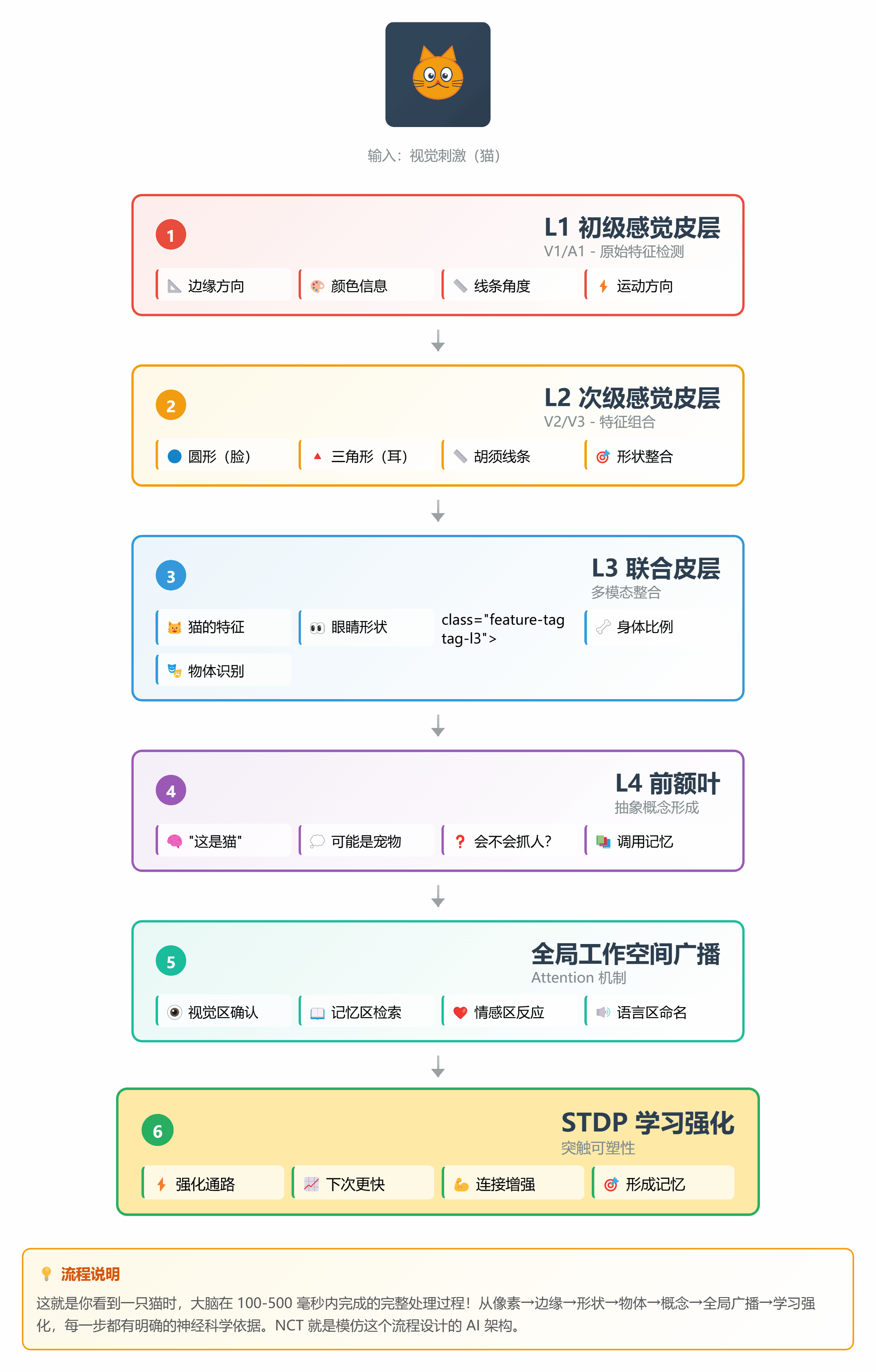
*图 8:从像素到概念的 7 步处理流程*
---
## 三、NCT vs 传统 AI:优势在哪里?
### 对比 1:可解释性
| 传统深度学习 | NCT |
|------------|-----|
| 黑盒:不知道为什么做出这个判断 | 白盒:每一步都有明确的神经历论支撑 |
| "我觉得这是猫" | "因为检测到尖耳、圆脸、胡须,且符合猫的预测模型" |
---
### 对比 2:样本效率
| 传统深度学习 | NCT |
|------------|-----|
| 需要上万张猫的图片训练 | 看过几只猫就能形成概念 |
| 纯数据驱动 | 结合先验知识(预测编码) |
---
### 对比 3:能耗
| 传统深度学习 | NCT |
|------------|-----|
| 训练一个大模型 = 5 辆汽车终身碳排放 | 预测编码减少 90% 冗余计算 |
| 暴力计算 | 只处理"意外"(预测误差) |
---
### 对比 4:泛化能力
| 传统深度学习 | NCT |
|------------|-----|
| 训练集和测试集必须相似 | 基于因果推理,能应对全新场景 |
| 遇到没见过的就不会 | 能用已有知识推理新事物 |
---
## 四、动手实验:用代码理解 NCT
光说不练假把式。让我们看几个简单的代码示例,帮你直观理解 NCT 的原理。
### 实验 1:模拟 STDP 规则
```python
import numpy as np
import matplotlib.pyplot as plt
# 简化的 STDP 规则
def stdp_curve(delta_t, A_plus=0.01, A_minus=0.012, tau=20.0):
"""
STDP 曲线:时间差决定权重变化
delta_t > 0: A 先于 B,权重增加
delta_t < 0: B 先于 A,权重减少
"""
if delta_t > 0:
return A_plus * np.exp(-delta_t / tau)
else:
return -A_minus * np.exp(delta_t / tau)
# 画图展示
delta_ts = np.linspace(-100, 100, 200)
changes = [stdp_curve(dt) for dt in delta_ts]
plt.figure(figsize=(10, 6))
plt.plot(delta_ts, changes, 'b-', linewidth=2)
plt.axhline(y=0, color='k', linestyle='--', alpha=0.3)
plt.axvline(x=0, color='k', linestyle='--', alpha=0.3)
plt.xlabel('时间差 (ms)')
plt.ylabel('突触权重变化')
plt.title('STDP 规则:时间决定强弱')
plt.grid(True, alpha=0.3)
plt.savefig('stdp_simple.png', dpi=150)
plt.show()
```
**运行结果**:你会看到一个十字交叉的曲线,完美展示了"早起的鸟儿有虫吃"的规则。
---
### 实验 2:模拟注意力机制
```python
import torch
import torch.nn.functional as F
# 简化的注意力计算
def simple_attention(query, keys, values):
"""
query: 你想找什么 (1×d)
keys: 候选项的特征 (n×d)
values: 候选项的内容 (n×d)
"""
# 计算相似度
scores = torch.matmul(query, keys.T) / np.sqrt(query.shape[1])
# 归一化成概率
weights = F.softmax(scores, dim=-1)
# 加权求和
output = torch.matmul(weights, values)
return output, weights
# 举个例子:在句子中找"猫"的相关词
sentence = "那只可爱的猫咪正在草地上玩耍"
words = ["那只", "可爱的", "猫", "正在", "草地", "玩耍"]
# 假设每个词有一个简单的向量表示(这里用随机数代替)
torch.manual_seed(42)
word_embeddings = torch.randn(6, 8) # 6 个词,每个词 8 维
query = word_embeddings[2:3] # "猫"的向量
output, attention_weights = simple_attention(query, word_embeddings, word_embeddings)
print("注意力权重:")
for word, weight in zip(words, attention_weights[0]):
print(f"{word}: {weight:.4f}")
```
**运行结果**:你会发现"可爱的"和"猫"的权重最高,因为它们语义最相关!
---
### 实验 3:模拟预测编码
```python
class SimplePredictiveCoder:
"""简化的预测编码器"""
def __init__(self):
self.prediction = 0.5 # 初始预测
self.learning_rate = 0.1
def update(self, actual_input):
# 计算预测误差
prediction_error = actual_input - self.prediction
# 更新预测(减小误差)
self.prediction += self.learning_rate * prediction_error
return prediction_error, self.prediction
# 模拟训练过程
coder = SimplePredictiveCoder()
inputs = [0.6, 0.7, 0.65, 0.72, 0.68, 0.7, 0.71, 0.69, 0.7, 0.7]
print("预测编码学习过程:")
print(f"{'步数':<6} {'输入':<8} {'预测':<8} {'误差':<8} {'新预测':<8}")
print("-" * 40)
for i, actual in enumerate(inputs):
error, new_pred = coder.update(actual)
print(f"{i:<6} {actual:<8.3f} {coder.prediction-error:<8.3f} {error:<8.3f} {new_pred:<8.3f}")
```
**运行结果**:你会看到预测越来越接近实际输入,误差越来越小——这就是学习!
---
## 五、NCT 的应用前景
说了这么多原理,NCT 到底能用来做什么?
### 应用场景 1:更智能的 AI 助手
**现在的聊天机器人**:
- 只会根据统计规律回答
- 经常答非所问
- 没有真正的"理解"
**NCT 驱动的 AI**:
- 能真正理解你的意图(预测编码)
- 能集中注意力在关键信息上(Attention)
- 能从少量例子中学习(STDP)
- 能有逻辑地推理(全局工作空间)
---
### 应用场景 2:类脑计算机
**现在的计算机**:
- CPU 和内存分离(冯·诺依曼瓶颈)
- 功耗巨大(数据中心相当于一个小城市)
- 擅长计算,不擅长感知和推理
**NCT 启发的类脑芯片**:
- 存算一体(像大脑一样)
- 超低功耗(只处理预测误差)
- 既能计算,又能感知和推理
---
### 应用场景 3:意识障碍诊断
**临床应用**:
- 测量植物人的脑电 Φ 值
- Φ 值高:还有意识,只是无法表达
- Φ 值低:可能真的没有意识了
- 指导治疗和康复
---
### 应用场景 4:教育个性化
**传统教育**:
- 一刀切的教学方式
- 无法针对每个学生的特点
**NCT 驱动的教育 AI**:
- 预测每个学生的知识状态
- 动态调整教学节奏
- 精准定位薄弱环节
- 像一对一私教一样高效
---
## 六、总结:NCT 的核心思想
最后,让我们用**三句话**总结 NCT:
### 第一句:**大脑是最高效的计算机**
- 20 瓦功率(相当于一个灯泡)
- 却能处理视觉、语言、情感、推理等复杂任务
- 秘诀在于:预测编码 + 稀疏连接 + 事件驱动
### 第二句:**意识是整合的信息**
- 不是单个神经元的活动
- 而是数十亿神经元协同工作的涌现现象
- 就像交响乐,不是单个乐器,而是整体的和谐
### 第三句:**学习是预测的优化**
- 不是死记硬背
- 而是不断调整内部模型,让世界更好预测
- 自由能降低之日,就是你变聪明之时!
---
## 七、给读者的行动建议
读完这篇文章,你可以:
### 初学者:
1. **理解核心思想**:预测、整合、注意、学习
2. **观察生活**:注意自己的意识体验
3. **保持好奇**:对大脑和 AI 保持兴趣
### 进阶学习者:
1. **阅读前 4 篇技术文章**:深入理解数学原理
2. **学习 Python 编程**:动手实现简单版本
3. **学习神经科学基础**:了解大脑结构
### 研究者/工程师:
1. **阅读原始论文**:Global Workspace、IIT、Friston 等
2. **深入研究代码**:nct_modules 目录下的实现
3. **尝试改进**:提出自己的想法和变体
---
## 八、常见问题解答
### Q1: NCT 真的能产生意识吗?
**A**: 这是个深奥的哲学问题。从功能角度看,如果 NCT 能完美模拟人脑的所有认知功能,那它至少表现出"像是有意识"。但意识的主观体验(感质)是否能被创造,目前还没有定论。
### Q2: NCT 和 GPT 有什么区别?
**A**:
- **GPT**:纯数据驱动,统计学习,黑盒
- **NCT**:结合先验知识,预测编码,白盒
- **GPT**:需要海量数据
- **NCT**:小样本学习
- **GPT**:只知道下一个词
- **NCT**:有全局理解和推理
### Q3: 中学生能学会这些吗?
**A**: 绝对可以!这篇文章就是证明。关键是:
- 用比喻理解抽象概念
- 用例子理解原理
- 循序渐进,不要急于求成
### Q4: NCT 什么时候能商用?
**A**: 目前还在研发阶段。挑战包括:
- 需要更多实验验证
- 需要优化性能
- 需要开发易用的 API
但我们相信,随着 AGI 的发展,NCT 的理念会被越来越多的系统采用。
---
## 下一步:模块二预告
模块一我们打下了理论基础。接下来,模块二将深入**神经科学**:
- **第 5 篇**:大脑皮层分层详解(从解剖学到计算)
- **第 6 篇**:海马体与记忆巩固(位置细胞到情景记忆)
- **第 7 篇**:丘脑 - 皮层振荡同步(Gamma 波的奥秘)
- **第 8 篇**:镜像神经元与社会认知(共情的神经基础)
敬请期待!
---
## 参考文献与延伸阅读
1. **通俗读物**:
- 《意识探秘》(Christof Koch)
- 《预测心智》(Andy Clark)
- 《行为》(Robert Sapolsky)
2. **科普视频**:
- YouTube: "Global Workspace Theory Explained"
- B 站:"预测编码入门"
3. **在线课程**:
- Coursera: "Computational Neuroscience" (UW)
- edX: "Introduction to Deep Learning"
---
**🔗 项目 GitHub**:https://github.com/wyg5208/nct.git
**💬 欢迎讨论**:如果你有任何问题或想法,欢迎在评论区留言!
---
*下一篇:模块二第 5 篇《大脑皮层分层详解——从 V1 到前额叶的计算之旅》*


