<!-- markdown -->
# **Decision Trees: Concepts, Principles, Development History, Characteristics, and Applications**
---
## Abstract
Decision trees are a widely used machine learning and decision analysis method known for their interpretability, simplicity, and versatility. This paper provides a comprehensive overview of decision trees, including their conceptual foundation, underlying principles, historical development, distinctive features, and typical applications across various domains such as business, healthcare, finance, and engineering. The study also discusses the advantages and limitations of decision tree models and highlights their relevance in modern data-driven decision-making.
**Keywords:** Decision Tree, Machine Learning, Data Mining, Classification, Regression, Decision Analysis
---
## 1. Introduction
In an increasingly data-rich world, decision-making has evolved from intuition-based strategies to data-driven methodologies. Among various analytical tools, **decision trees** stand out due to their intuitive structure, ease of interpretation, and effectiveness in both classification and regression tasks. This paper aims to provide a detailed exploration of decision trees, focusing on their theoretical underpinnings, evolution over time, key characteristics, and practical applications.
---
## 2. Concept of Decision Trees
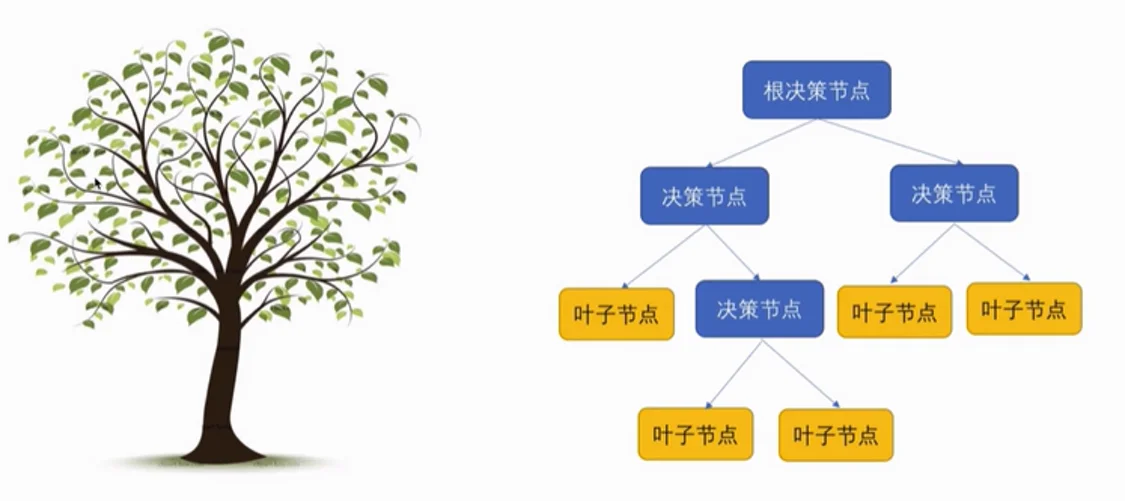
A **decision tree** is a supervised machine learning algorithm that uses a tree-like model of decisions and their possible consequences. It is used for both **classification** (predicting categories) and **regression** (predicting numerical values). Each internal node in the tree represents a test on an attribute (e.g., "Is income > $50k?"), each branch represents the outcome of the test, and each leaf node represents a final decision or outcome.
### 2.1 Basic Structure
- **Root Node**: Represents the entire dataset and is the starting point.
- **Internal Nodes**: Represent feature tests (e.g., age, income).
- **Branches**: Represent the outcomes of a test (e.g., yes/no).
- **Leaf Nodes**: Represent class labels (in classification) or numerical values (in regression).

*(Example of a simple decision tree for loan approval)*
---
## 3. Principles Behind Decision Trees
### 3.1 Splitting Criteria
The core principle of building a decision tree involves recursively splitting the dataset into subsets based on the values of input features. Common splitting criteria include:
- **Gini Impurity**: Measures how often a randomly chosen element would be incorrectly labeled if it were randomly labeled according to the distribution of labels in the subset.
- **Entropy & Information Gain**: Entropy measures disorder, while information gain measures the reduction in entropy after a dataset is split.
- **Variance Reduction**: Used in regression trees to minimize the variance within child nodes.
### 3.2 Pruning
To avoid overfitting, decision trees employ **pruning**, which removes sections of the tree that provide little power in predicting target values. Pruning can be:
- **Pre-pruning**: Halting tree growth early based on conditions like depth or minimum samples per node.
- **Post-pruning**: Removing branches from a fully grown tree.
---
## 4. Historical Development of Decision Trees
The concept of decision trees has roots in early statistical and decision theory. However, their formalization in computer science and machine learning began in the late 20th century.
### 4.1 Early Foundations
- **1950s–1960s**: Decision trees were initially developed in operations research and statistics for structured decision-making under uncertainty.
- **1984**: The **CART (Classification and Regression Tree)** algorithm was introduced by Breiman, Friedman, Stone, and Olshen, providing a systematic approach to constructing binary decision trees.
- **1986**: Ross Quinlan introduced **ID3 (Iterative Dichotomiser 3)**, which used entropy and information gain to build trees.
- **1993**: Quinlan improved ID3 with the **C4.5** algorithm, which could handle continuous attributes and missing data.
### 4.2 Modern Developments
- **Ensemble Methods**: Decision trees serve as base learners in ensemble techniques like **Random Forests** and **Gradient Boosting Machines (GBMs)**.
- **Integration with Big Data**: With advances in computing power and data availability, decision trees have become integral to automated decision systems and AI pipelines.
---
## 5. Key Characteristics of Decision Trees
| Feature | Description |
|--------|-------------|
| **Interpretability** | Easy to understand and visualize; rules can be interpreted by humans without technical expertise. |
| **Non-parametric** | Makes no assumptions about the distribution of data. |
| **Feature Selection** | Automatically selects relevant features during training. |
| **Robustness** | Handles outliers and missing values well. |
| **Scalability** | Efficient for medium-sized datasets; less so for very large datasets. |
| **Bias-Variance Trade-off** | Tends to overfit deep trees; pruning and ensembling help reduce variance. |
---
## 6. Typical Applications
Decision trees are versatile and widely applied across many fields.
### 6.1 Business and Marketing
- **Customer Segmentation**: Group customers based on purchasing behavior.
- **Churn Prediction**: Identify customers likely to stop using a service.
- **Credit Scoring**: Predict loan default risk.
### 6.2 Healthcare
- **Diagnosis Support Systems**: Aid in diagnosing diseases based on symptoms.
- **Treatment Planning**: Recommend treatment options based on patient history.
### 6.3 Finance
- **Fraud Detection**: Identify suspicious transactions.
- **Stock Market Prediction**: Forecast stock prices based on historical data.
### 6.4 Engineering
- **Fault Diagnosis**: Detect system failures in manufacturing processes.
- **Predictive Maintenance**: Schedule maintenance based on equipment usage patterns.
### 6.5 Environmental Science
- **Species Classification**: Identify species based on environmental features.
- **Climate Modeling**: Predict climate change impacts using weather data.
---
## 7. Decision Trees vs. Other Models
| Model | Strengths | Limitations | Comparison with Decision Trees |
|-------|-----------|-------------|-------------------------------|
| **Logistic Regression** | Simple, interpretable, fast | Only linear relationships | Less flexible but more stable |
| **Neural Networks** | Powerful, nonlinear modeling | Black-box, hard to interpret | More accurate but less transparent |
| **Support Vector Machines (SVMs)** | Effective in high dimensions | Requires tuning, not interpretable | Better for small data with complex boundaries |
| **Ensemble Methods (e.g., Random Forests)** | High accuracy, robust | Computationally intensive | Decision trees are building blocks |
---
## 8. Challenges and Limitations
Despite their popularity, decision trees face several challenges:
- **Overfitting**: Deep trees may capture noise instead of patterns.
- **Instability**: Small changes in data can lead to completely different trees.
- **Bias Toward Dominant Classes**: In imbalanced datasets, minority classes may be overlooked.
- **Limited Expressiveness**: Cannot model complex relationships as effectively as neural networks.
---
## 9. Conclusion
Decision trees remain a cornerstone of machine learning and decision science due to their interpretability, flexibility, and wide range of applications. From their origins in statistical decision theory to their integration into advanced ensemble methods, decision trees continue to evolve alongside technological advancements. As organizations seek to make sense of growing volumes of data, the role of decision trees in explaining and guiding decisions remains indispensable.
---
## References
1. Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). *Classification and Regression Trees*. CRC Press.
2. Quinlan, J. R. (1986). Induction of decision trees. *Machine Learning*, 1(1), 81–106.
3. Quinlan, J. R. (1993). *C4.5: Programs for Machine Learning*. Morgan Kaufmann Publishers.
4. Hastie, T., Tibshirani, R., & Friedman, J. (2009). *The Elements of Statistical Learning*. Springer.
5. Rokach, L., & Maimon, O. (2015). *Data Mining with Decision Trees: Theory and Applications*. World Scientific Publishing.
---
If you'd like this paper converted into a LaTeX document or formatted for publication (e.g., IEEE, ACM, APA style), feel free to ask!

 --°C
--
·
--%
·
--
--°C
--
·
--%
·
--